
| Name: | Peter Kocsis |
|---|---|
| Position: | Ph.D Candidate |
| E-Mail: | peter.kocsis@tum.de |
| Phone: | +49 (89) 289 - 18164 |
| Room No: | 02.07.038 |
Bio
I am Peter. I finished my Bachelor studies as a Mechatronics engineer in Hungary, then I moved to Munich and did the Master of Robotics, Cognition, Intelligence at TUM. I previously worked on Active Learning and Reinforcement Learning for control and autonomous driving.Research Interest
Dynamic 3D Reconstruction, Reinforcement Learning and Information/Sensor Fusion techniques using learning based methodologies.Publications
2026

| Intrinsic Image Fusion for Multi-View 3D Material Reconstruction |
|---|
| Peter Kocsis, Lukas Höllein, Matthias Nießner |
| CVPR 2026 |
| Relightable 3D reconstruction is the core of numerous applications. Optimization-based methods usually struggle to produce clean and sharp predictions due to path tracing noise, insufficient view coverage and imperfect rendering models. Data-driven methods are able to estimate sharp and consistent material maps, but fail to generalize to real-world scenes and to maintain physical correctness. Our method combines the best of both words. We propose a robust fusion method to aggregate inconsistent single-view material predictions. Then, we fine-tune these predictions using inverse path tracing and reach physically grounded, clean material maps. |
| [video][bibtex][project page] |
2025

| IntrinsiX: High-Quality PBR Generation using Image Priors |
|---|
| Peter Kocsis, Lukas Höllein, Matthias Nießner |
| NeurIPS 2025 |
| Recent generative models directly create shaded images, without any explicit material and shading representation. From text input, we generate renderable PBR maps. We first train separate LoRA modules for the intrinsic properties of albedo, rough/metal, normal. Then, we introduce cross-intrinsic attention using a rerendering loss with importance-weighted light sampling to enable coherent PBR generation. Next to editable image generation, our predictions can be distilled into room-scale scenes using SDS for large-scale PBR texture generation. Our method outperforms text -> image -> PBR methods both in generalization and quality, since directly generating PBR maps does not suffer from the inherent ambiguity of intrinsic image decomposition. In addition, our design choice facilitates SDS-based PBR texture distillation. |
| [video][bibtex][project page] |
2024

| LightIt: Illumination Modeling and Control for Diffusion Models |
|---|
| Peter Kocsis, Julien Philip, Kalyan Sunkavalli, Matthias Nießner, Yannick Hold-Geoffroy |
| CVPR 2024 |
| Recent generative methods lack lighting control, which is crucial to numerous artistic aspects. We propose to condition the generation on shading and normal maps. We model the lighting with single bounce shading, which includes cast shadows. We first train a shading estimation module to generate a dataset of real-world images and shading pairs. Then, we train a control network using the estimated shading and normals as input. |
| [video][bibtex][project page] |

| Intrinsic Image Diffusion for Single-view Material Estimation |
|---|
| Peter Kocsis, Vincent Sitzmann, Matthias Nießner |
| CVPR 2024 |
| Appearance decomposition is an ambiguous task and collecting real data is challenging. We utilize a pre-trained diffusion model and formulate the problem probabilistically. We fine-tune a pre-trained diffusion model conditioned on a single input image to adapt its image prior to the prediction of albedo, roughness and metallic maps. With our sharp material predictions, we optimize for spatially-varying lighting to enable photo-realistic material editing and relighting. |
| [video][bibtex][project page] |
2022
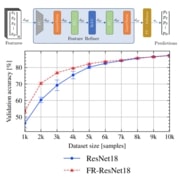
| The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes |
|---|
| Peter Kocsis, Peter Sukenik, Guillem Braso, Matthias Nießner, Laura Leal-Taixé, Ismail Elezi |
| NeurIPS 2022 |
| We show that adding fully-connected layers is beneficial for the generalization of convolutional networks in the tasks working in the low-data regime. Furthermore, we present a novel online joint knowledge distillation method (OJKD), which allows us to utilize additional final fully-connected layers during training but drop them during inference without a noticeable loss in performance. Doing so, we keep the same number of weights during test time. |
| [code][bibtex][project page] |