
| Name: | Shivangi Aneja |
|---|---|
| Position: | Ph.D Candidate |
| E-Mail: | shivangi.aneja@tum.de |
| Phone: | +49-89-289-18489 |
| Room No: | 02.07.041 |
Bio
Shivangi Aneja is a PhD student in Visual Computing Lab advised by Prof. Matthias Nießner. Prior to that, she completed her Master’s degree in Informatics from Technical University of Munich. She joined the lab during her master thesis, where she worked on “Generalized Zero and Few-Shot Transfer for Facial Forgery Detection”. She holds a Bachelor’s degree in Computer Science from the National Institute of Technology, India, where she graduated with a Gold Medal for academic excellence.
Research Interest
Computer Vision, Transfer LearningPublications
2025
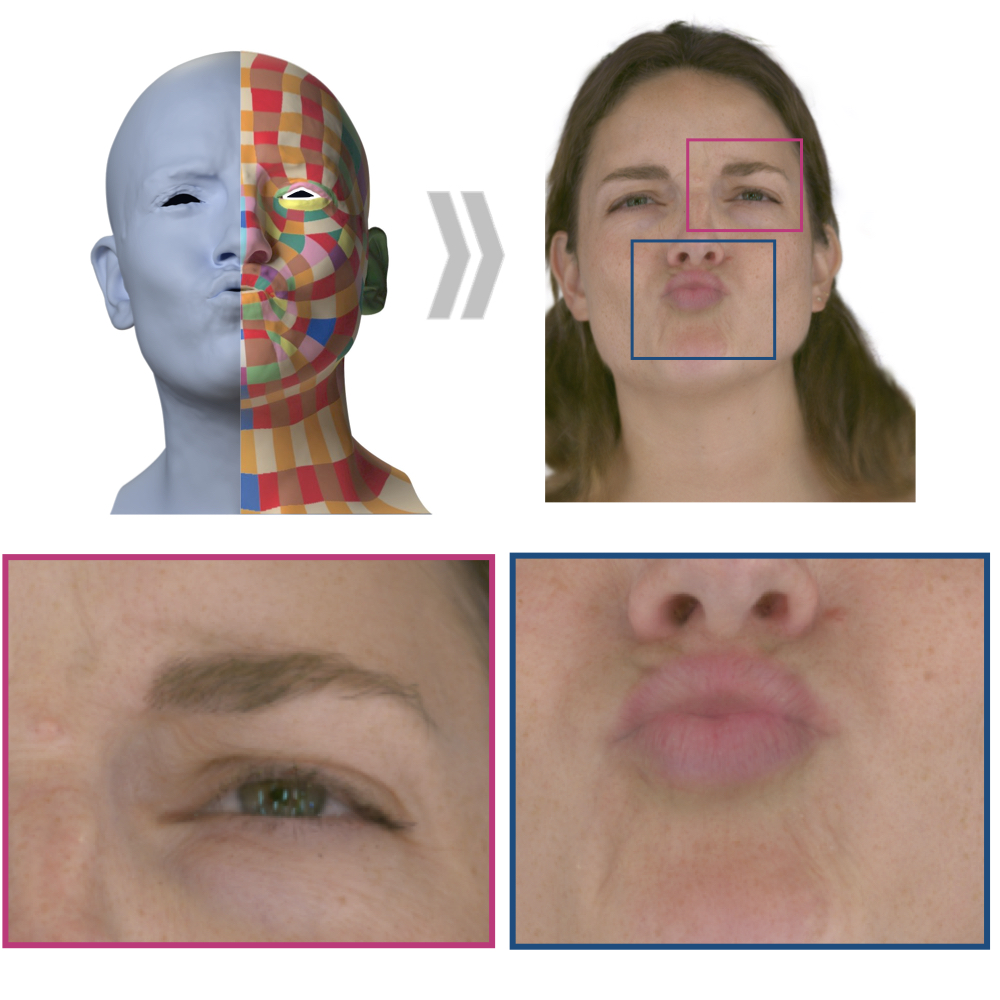
| ScaffoldAvatar: High-Fidelity Gaussian Avatars with Patch Expressions |
|---|
| Shivangi Aneja, Sebastian Weiss, Irene Baeza, Prashanth Chandran, Gaspard Zoss, Matthias Nießner, Derek Bradley |
| SIGGRAPH 2025 |
| ScaffoldAvatar presents a novel approach for reconstructing ultra-high fidelity animatable head avatars, which can be rendered in real-time. Our method operates on patch-based local expression features and synthesizes 3D Gaussians dynamically by leveraging tiny scaffold MLPs. We employ color-based densification and progressive training to obtain high-quality results and fast convergence. |
| [video][bibtex][project page] |
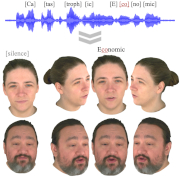
| GaussianSpeech: Audio-Driven Gaussian Avatars |
|---|
| Shivangi Aneja, Artem Sevastopolsky, Tobias Kirschstein, Justus Thies, Angela Dai, Matthias Nießner |
| ICCV 2025 |
| GaussianSpeech synthesizes high-fidelity animation sequences of photo-realistic, personalized 3D human head avatars from spoken audio. Our method can generate realistic and high-quality animations, including mouth interiors such as teeth, wrinkles, and specularities in the eyes. We handle diverse facial geometry, including hair buns and mustaches/beards, while effectively generalizing to in-the-wild audio clips. |
| [video][bibtex][project page] |
2024

| FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models |
|---|
| Shivangi Aneja, Justus Thies, Angela Dai, Matthias Nießner |
| CVPR 2024 |
| Given an input audio signal, FaceTalk proposes a diffusion-based approach to synthesize high-quality and temporally consistent 3D motion sequences of high-fidelity human heads as neural parametric head models. FaceTalk can generate detailed facial expressions including wrinkles and eye blinks alongside temporally synchronized mouth movements for diverse audio inputs including songs and foreign languages. |
| [video][bibtex][project page] |
2023
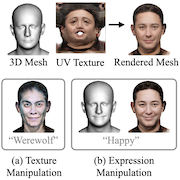
| ClipFace: Text-guided Editing of Textured 3D Morphable Models |
|---|
| Shivangi Aneja, Justus Thies, Angela Dai, Matthias Nießner |
| SIGGRAPH'23 |
| ClipFace learns a self-supervised generative model for jointly synthesizing geometry and texture leveraging 3D morphable face models, that can be guided by text prompts. For a given 3D mesh with fixed topology, we can generate arbitrary face textures as UV maps. The textured mesh can then be manipulated with text guidance to generate diverse set of textures and geometric expressions in 3D by altering (a) only the UV texture maps for Texture Manipulation and (b) both UV maps and mesh geometry for Expression Manipulation. |
| [video][bibtex][project page] |

| COSMOS: Catching Out-of-Context Misinformation with Self-Supervised Learning |
|---|
| Shivangi Aneja, Chris Bregler, Matthias Nießner |
| AAAI 2023 |
| Despite the recent attention to DeepFakes, one of the most prevalent ways to mislead audiences on social media is the use of unaltered images in a new but false context. To address these challenges and support fact-checkers, we propose a new method that automatically detects out-of-context image and text pairs. Our key insight is to leverage grounding of image with text to distinguish out-of-context scenarios that cannot be disambiguated with language alone. Check out the paper for more details. |
| [video][code][bibtex][project page] |
2022

| TAFIM: Targeted Adversarial Attacks against Facial Image Manipulations |
|---|
| Shivangi Aneja, Lev Markhasin, Matthias Nießner |
| ECCV 2022 |
| We introduce a novel data-driven approach that produces image-specific perturbations which are embedded in the original images to prevent face manipulation by causing the manipulation model to produce a predefined manipulation target. Compared to traditional adversarial attack baselines that optimize noise patterns for each image individually, our generalized model only needs a single forward pass, thus running orders of magnitude faster and allowing for easy integration in image processing stacks, even on resource-constrained devices like smartphones. Check out the paper for more details. |
| [video][code][bibtex][project page] |