
| Name: | Yawar Siddiqui |
|---|---|
| Position: | Ph.D Candidate |
| E-Mail: | yawar.siddiqui@tum.de |
| Phone: | +49-89-289-18489 |
| Room No: | 02.07.037 |
Bio
Hi! I'm Yawar. I did my Bachelor's in Computer Science in India and Master's from TU Munich. I worked on Active Learning for Semantic Segmentation as my Master Thesis with the Visual Computing Lab before joining as an intern. In the past, I've worked with Adobe Systems - Core technologies Imaging team in India, and as an intern with Disney Research, Zurich on Neck Tracking and Reconstruction.
Research Interest
2D-3D Scene Understanding, Human Body ReconstructionPublications
2024

| MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers |
|---|
| Yawar Siddiqui, Antonio Alliegro, Alexey Artemov, Tatiana Tommasi, Daniele Sirigatti, Vladislav Rosov, Angela Dai, Matthias Nießner |
| CVPR 2024 |
| MeshGPT creates triangle meshes by autoregressively sampling from a transformer model that has been trained to produce tokens from a learned geometric vocabulary. Our method generates clean, coherent, and compact meshes, characterized by sharp edges and high fidelity. |
| [video][bibtex][project page] |
2023

| Text2Tex: Text-driven Texture Synthesis via Diffusion Models |
|---|
| Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, Matthias Nießner |
| ICCV 2023 |
| We present Text2Tex, a novel method for generating high-quality textures for 3D meshes from the given text prompts. Our method incorporates inpainting into a pre-trained depth-aware image diffusion model to progressively synthesize high resolution partial textures from multiple viewpoints. Furthermore, we propose an automatic view sequence generation scheme to determine the next best view for updating the partial texture. |
| [video][bibtex][project page] |

| Panoptic Lifting for 3D Scene Understanding with Neural Fields |
|---|
| Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bulo, Norman Müller, Matthias Nießner, Angela Dai, Peter Kontschieder |
| CVPR 2023 |
| Given only RGB images of an in-the-wild scene as input, Panoptic Lifting optimizes a panoptic radiance field which can be queried for color, depth, semantics, and instances for any point in space. |
| [bibtex][project page] |
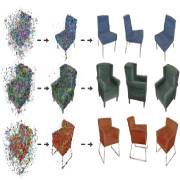
| DiffRF: Rendering-guided 3D Radiance Field Diffusion |
|---|
| Norman Müller, Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bulo, Peter Kontschieder, Matthias Nießner |
| CVPR 2023 |
| DiffRF is a denoising diffusion probabilistic model directly operating on 3D radiance fields and trained with an additional volumetric rendering loss. This enables learning strong radiance priors with high rendering quality and accurate geometry. This appraoch naturally enables tasks like 3D masked completion or image-to-volume synthesis. |
| [video][bibtex][project page] |
2022

| Texturify: Generating Textures on 3D Shape Surfaces |
|---|
| Yawar Siddiqui, Justus Thies, Fangchang Ma, Qi Shan, Matthias Nießner, Angela Dai |
| ECCV 2022 |
| Texturify learns to generate geometry-aware textures for untextured collections of 3D objects. Our method trains from only a collection of images and a collection of untextured shapes, which are both often available, without requiring any explicit 3D color supervision or shape-image correspondence. Textures are created directly on the surface of a given 3D shape, enabling generation of high-quality, compelling textured 3D shapes. |
| [bibtex][project page] |
2021

| RetrievalFuse: Neural 3D Scene Reconstruction with a Database |
|---|
| Yawar Siddiqui, Justus Thies, Fangchang Ma, Qi Shan, Matthias Nießner, Angela Dai |
| ICCV 2021 |
| We introduce a new 3D reconstruction method that directly leverages scene geometry from the training database, facilitating transfer of coherent structures and local detail from train scene geometry. |
| [video][code][bibtex][project page] |

| SPSG: Self-Supervised Photometric Scene Generation from RGB-D Scans |
|---|
| Angela Dai, Yawar Siddiqui, Justus Thies, Julien Valentin, Matthias Nießner |
| CVPR 2021 |
| We present SPSG, a novel approach to generate high-quality, colored 3D models of scenes from RGB-D scan observations by learning to infer unobserved scene geometry and color in a self-supervised fashion. Rather than relying on 3D reconstruction losses to inform our 3D geometry and color reconstruction, we propose adversarial and perceptual losses operating on 2D renderings in order to achieve high-resolution, high-quality colored reconstructions of scenes. |
| [video][code][bibtex][project page] |
2020
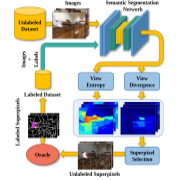
| ViewAL: Active Learning with Viewpoint Entropy for Semantic Segmentation |
|---|
| Yawar Siddiqui, Julien Valentin, Matthias Nießner |
| CVPR 2020 |
| We propose ViewAL, a novel active learning strategy for semantic segmentation that exploits viewpoint consistency in multi-view datasets. |
| [video][code][bibtex][project page] |