3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation
Technical University of Munich
Proceedings of the European Conference on Computer Vision (ECCV 2018)
Abstract
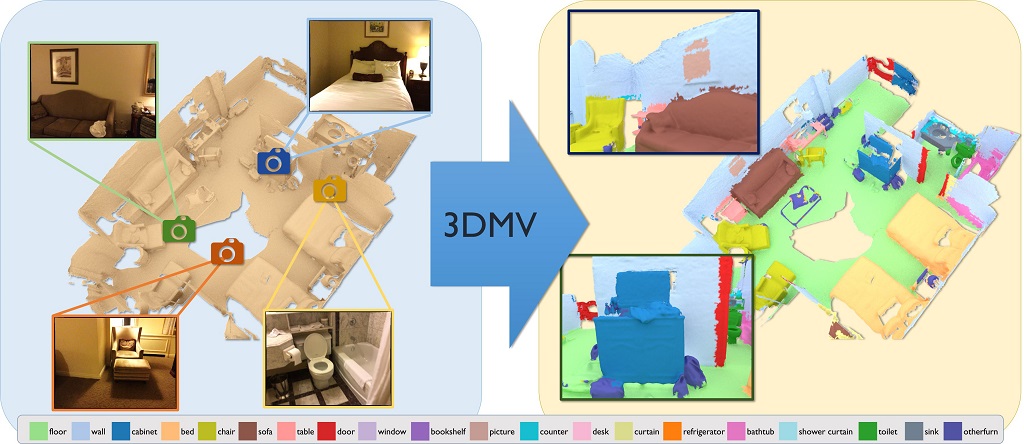
We present 3DMV, a novel method for 3D semantic scene segmentation of RGB-D scans in indoor environments using a joint 3D-multi-view prediction network. In contrast to existing methods that either use geometry or RGB data as input for this task, we combine both data modalities in a joint, end-to-end network architecture. Rather than simply projecting color data into a volumetric grid and operating solely in 3D -- which would result in insufficient detail -- we first extract feature maps from associated RGB images. These features are then mapped into the volumetric feature grid of a 3D network using a differentiable backprojection layer. Since our target is 3D scanning scenarios with possibly many frames, we use a multi-view pooling approach in order to handle a varying number of RGB input views. This learned combination of RGB and geometric features with our joint 2D-3D architecture achieves significantly better results than existing baselines. For instance, our final result on the ScanNet 3D segmentation benchmark increases from 52.8% to 75% accuracy compared to existing volumetric architectures.
 Bibtex
Bibtex