
| Name: | Matthias Nießner |
|---|---|
| Position: | Professor |
| E-Mail: | niessner@tum.de |
| Phone: | contact via email only |
| Room No: | 02.07.042 |
Bio
Dr. Matthias Nießner is a Professor at the Technical University of Munich, where he leads the Visual Computing Lab. Before, he was a Visiting Assistant Professor at Stanford University. Prof. Nießner’s research lies at the intersection of computer vision, graphics, and machine learning, where he is particularly interested in cutting-edge techniques for 3D reconstruction, semantic 3D scene understanding, video editing, and AI-driven video synthesis. In total, he has published over 150 academic publications, including 25 papers at the prestigious ACM Transactions on Graphics (SIGGRAPH / SIGGRAPH Asia) journal and 55 works at the leading vision conferences (CVPR, ECCV, ICCV); several of these works won best paper awards, including at SIGCHI’14, HPG’15, SPG’18, and the SIGGRAPH’16 Emerging Technologies Award for the best Live Demo.Prof. Nießner’s work enjoys wide media coverage, with many articles featured in main-stream media including the New York Times, Wall Street Journal, Spiegel, MIT Technological Review, and many more, and his was work led to several TV appearances such as on Jimmy Kimmel Live, where Prof. Nießner demonstrated the popular Face2Face technique; Prof. Nießner’s academic Youtube channel currently has over 5 million views.
For his work, Prof. Nießner received several awards: he is a TUM-IAS Rudolph Moessbauer Fellow (2017 – ongoing), he won the Google Faculty Award for Machine Perception (2017), the Nvidia Professor Partnership Award (2018), as well as the prestigious ERC Starting Grant 2018 which comes with 1.5 million Euro in research funding; in 2019, he received the Eurographics Young Researcher Award honoring the best upcoming graphics researcher in Europe.
In addition to his academic impact, Prof. Nießner is a co-founder and director of Synthesia Inc., a leading startup dedicated to democratize synthetic media generation with cutting-edge AI-driven video synthesis technology.
Important: For PhD, Visiting/Intern, and PostDoc positions, carefully follow the Openings instructions. Please do not send applications to me personally via email!
Publications
Preprints
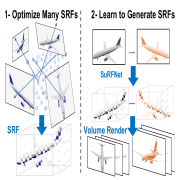
| SPARF: Large-Scale Learning of 3D Sparse Radiance Fields from Few Input Images |
|---|
| Abdullah Hamdi, Bernard Ghanem, Matthias Nießner |
| arXiv |
| SPARF is a large-scale sparse radiance field dataset consisting of ~ 1 million SRFs with multiple voxel resolutions (32, 128, and 512) and 17 million posed images with a resolution of 400 X 400. Furthermore, we propose SuRFNet, a pipline to generate SRFs conditioned on input images, achieving SOTA on ShapeNet novel views synthesis from one or few input images. |
| [video][bibtex][project page] |
2026

| Pix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image |
|---|
| Simon Giebenhain, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Zhe Chen, Matthias Nießner |
| ECCV 2026 |
| Pix2NPHM is the first feed-forward regressor for neural parametric head models. We focus on large-scale 3D dataset registration and pseudo-geometric supervision on large in-the-wild video collections, to learn a prior over NPHM parameters, enabling fast and robust inference. |
| [video][bibtex][project page] |

| Seen2Scene: Completing Realistic 3D Scenes with Visibility-Guided Flow |
|---|
| Quan Meng, Yujin Chen, Lei Li, Matthias Nießner, Angela Dai |
| ECCV 2026 |
| Seen2Scene is a visibility-guided flow matching approach for 3D scene completion and generation, trained directly on incomplete, real-world 3D scans. By explicitly masking unknown regions, it learns from partial observations and predicts high-fidelity, geometrically complete, and structurally coherent scene geometry in unobserved areas, conditioned on observed regions. |
| [video][bibtex][project page] |

| DreamEdit3D: Personalization of Multi-View Diffusion Models for 3D Editing |
|---|
| Jinxin Ai, Matthias Nießner, Ziya Erkoç |
| ECCV 2026 |
| DreamEdit3D is a framework for personalized 3D scene editing by leveraging multi-view diffusion models. The approach enables users to edit 3D scenes with fine-grained control through personalized text-driven modifications while maintaining multi-view consistency. |
| [video][bibtex][project page] |

| TriFlow: Generating Artist-Like 3D Mesh Topology via Nearest-Vertex Vector Fields |
|---|
| Haoxuan Li, Ziya Erkoç, Daniele Sirigatti, Vladislav Rosov, Lei Li, Angela Dai, Matthias Nießner |
| ECCV 2026 |
| TriFlow is a generative method for generating mesh topologies based on geometry. By defining a Nearest Vertex Vector Field on the surface of the geometry, TriFlow effectively applies 3D latent flow methods to topology generation, offering superior topology quality and generation speed compared to previous methods. |
| [video][bibtex][project page] |

| WorldAgents: Can Foundation Image Models be Agents for 3D World Models? |
|---|
| Ziya Erkoç, Angela Dai, Matthias Nießner |
| ECCV 2026 |
| WorldAgents is a multi-agent method that leverages 2D foundation image and vision-language models, acting as directors, generators, and verifiers, to iteratively generate, curate, and reconstruct coherent, explorable 3D environments. |
| [video][bibtex][project page] |

| GaussianGPT: Towards Autoregressive 3D Gaussian Scene Generation |
|---|
| Nicolas von Lützow, Barbara Rössle, Katharina Schmid, Matthias Nießner |
| ECCV 2026 |
| GaussianGPT explores autoregressive 3D scene generation by directly predicting sequences of discrete 3D Gaussian tokens. By combining a vector-quantized sparse 3D autoencoder with a causal transformer, it constructs spatial structure and appearance step by step, enabling controllable generation, scene completion, and outpainting. |
| [video][bibtex][project page] |

| Face Anything: 4D Face Reconstruction from Any Image Sequence |
|---|
| Umut Kocasarı, Simon Giebenhain, Richard Shaw, Matthias Nießner |
| ECCV 2026 |
| Face Anything is a unified feed-forward model for high-fidelity 4D face reconstruction and dense tracking from arbitrary image sequences. The key idea is canonical facial point prediction, a representation that assigns each pixel a normalized facial coordinate in a shared canonical space. This formulation transforms dense tracking and dynamic reconstruction into a single canonical reconstruction problem, producing temporally consistent geometry and reliable correspondences. |
| [video][bibtex][project page] |

| World Reconstruction From Inconsistent Views |
|---|
| Lukas Höllein, Matthias Nießner |
| ECCV 2026 |
| Our method reconstructs 3D worlds from video diffusion models using non-rigid alignment to resolve inherent 3D inconsistencies in the generated sequences. |
| [video][bibtex][project page] |

| MeshRipple: Structured Autoregressive Generation of Artist-Meshes |
|---|
| Junkai Lin, Hang Long, Huipeng Guo, Jielei Zhang, Jiayi Yang, Tianle Guo, Yang Yang, Jianwen Li, Wenxiao Zhang, Matthias Nießner, Wei Yang |
| CVPR 2026 |
| MeshRipple generates large, high-fidelity 3D meshes using a topology-aligned autoregressive framework. We introduce Ripple Tokenization to expand the mesh outward from an active frontier, resolving long-range geometric dependencies and eliminating the holes common in previous autoregressive methods. |
| [video][bibtex][project page] |

| Intrinsic Image Fusion for Multi-View 3D Material Reconstruction |
|---|
| Peter Kocsis, Lukas Höllein, Matthias Nießner |
| CVPR 2026 |
| Relightable 3D reconstruction is the core of numerous applications. Optimization-based methods usually struggle to produce clean and sharp predictions due to path tracing noise, insufficient view coverage and imperfect rendering models. Data-driven methods are able to estimate sharp and consistent material maps, but fail to generalize to real-world scenes and to maintain physical correctness. Our method combines the best of both words. We propose a robust fusion method to aggregate inconsistent single-view material predictions. Then, we fine-tune these predictions using inverse path tracing and reach physically grounded, clean material maps. |
| [video][bibtex][project page] |

| PercHead: Perceptual Head Model for Single-Image 3D Head Reconstruction & Editing |
|---|
| Antonio Oroz, Matthias Nießner, Tobias Kirschstein |
| CVPR 2026 |
| PercHead reconstructs 3D heads from a single input image and enables disentangled 3D editing, using a novel perceptual loss built on generalized vision models that replaces standard low-level losses for improved visual quality and robustness to extreme viewpoints. |
| [video][bibtex][project page] |

| FlexAvatar: Learning Complete 3D Head Avatars with Partial Supervision |
|---|
| Tobias Kirschstein, Simon Giebenhain, Matthias Nießner |
| CVPR 2026 |
| FlexAvatar creates high-quality and complete 3D head avatars from as few as a single input image. Learning such generalized 3D head avatars from monocular portrait videos suffers from entanglement between driving signal and target viewpoint. To address this, we propose a transformer-based 3D portrait animation model with learnable data source tokens, so-called bias sinks, which enables unified training across monocular and multi-view datasets. The result is a flexible model that can create a 3D avatar from any number of images within just 2 minutes and animate it in real-time. |
| [video][bibtex][project page] |
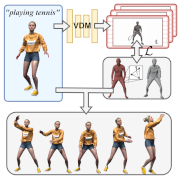
| Animating the Uncaptured: Humanoid Mesh Animation with Video Diffusion Models |
|---|
| Marc Benedí San Millán, Angela Dai, Matthias Nießner |
| ICLR 2026 |
| Animating the Uncaptured (AtU) generates 4D humanoid animations from text prompts, without requiring training on limited motion capture data. Instead, it leverages the strong generalized motion priors of video diffusion models, transferring motion to the 3D mesh using an SMPL-based deformation proxy. |
| [video][bibtex][project page] |

| Pixel3DMM: Versatile Screen-Space Priors for Single-Image 3D Face Reconstruction |
|---|
| Simon Giebenhain, Tobias Kirschstein, Martin Rünz, Lourdes Agapito, Matthias Nießner |
| ICLR 2026 |
| Pixel3DMM is a state-of-the art FLAME tracker using face-specific domain expert ViT predictions for pixel-aligned geometric cues, i.e. uv-coordinartes and surface normals. The combination of DINOv2 backbone and large-scale 3D face dataset processing result in extremly robust tracking on in-the-wild data. |
| [video][bibtex][project page] |
2025

| WorldExplorer: Towards Generating Fully Navigable 3D Scenes |
|---|
| Manuel-Andreas Schneider, Lukas Höllein, Matthias Nießner |
| SIGGRAPH Asia 2025 |
| WorldExplorer generates 3D scenes from a given text prompt using camera-guided video diffusion models. |
| [video][bibtex][project page] |

| LinPrim: Linear Primitives for Differentiable Volumetric Rendering |
|---|
| Nicolas von Lützow, Matthias Nießner |
| NeurIPS 2025 |
| We develop a differentiable volumetric rendering framework that uses transparent polyhedral primitives to represent scenes and render them in real-time. The primitives offer a bounded and compact representation that improves performance on specular areas and achieves better depth estimates while remaining compatible with advances developed for 3D Gaussians. |
| [video][bibtex][project page] |

| ROGR: Relightable 3D Objects using Generative Relighting |
|---|
| Jiapeng Tang, Matthew Levine, Dor Verbin, Stephan Garbin, Matthias Nießner, Ricardo Martin-Brualla, Pratul P. Srinivasan, Philipp Henzler |
| NeurIPS 2025 Spotlight |
| Given an image collection under unknown lighting, ROGR reconstructs a relightable neural radiance field, that can be rendered under any novel environment map without further optimization, on-the-fly relighting and novel view synthesis. |
| [code][bibtex][project page] |

| BecomingLit: Relightable Gaussian Avatars with Hybrid Neural Shading |
|---|
| Jonathan Schmidt, Simon Giebenhain, Matthias Nießner |
| NeurIPS 2025 |
| BecomingLit reconstructs intrinsically decomposed head avatars based on 3D Gaussian primitives for real-time relighting and animation. To train our avatars, we introduce a novel multi-view light stage dataset. |
| [video][bibtex][project page] |

| PBR-SR: Mesh PBR Texture Super Resolution from 2D Image Priors |
|---|
| Yujin Chen, Yinyu Nie, Benjamin Ummenhofer, Reiner Birkl, Michael Paulitsch, Matthias Nießner |
| NeurIPS 2025 |
| PBR-SR is a zero-shot approach for super-resolving physically based rendering (PBR) textures, using a pretrained super-resolution model and iterative optimization with differentiable rendering. The method refines high-resolution textures by minimizing deviations between super-resolution priors and multi-view renderings, while enforcing identity constraints to preserve fidelity to the low-resolution input. It requires no additional training or data, and consistently produces high-quality PBR textures for both artist-designed and AI-generated meshes. |
| [video][bibtex][project page] |

| IntrinsiX: High-Quality PBR Generation using Image Priors |
|---|
| Peter Kocsis, Lukas Höllein, Matthias Nießner |
| NeurIPS 2025 |
| Recent generative models directly create shaded images, without any explicit material and shading representation. From text input, we generate renderable PBR maps. We first train separate LoRA modules for the intrinsic properties of albedo, rough/metal, normal. Then, we introduce cross-intrinsic attention using a rerendering loss with importance-weighted light sampling to enable coherent PBR generation. Next to editable image generation, our predictions can be distilled into room-scale scenes using SDS for large-scale PBR texture generation. Our method outperforms text -> image -> PBR methods both in generalization and quality, since directly generating PBR maps does not suffer from the inherent ambiguity of intrinsic image decomposition. In addition, our design choice facilitates SDS-based PBR texture distillation. |
| [video][bibtex][project page] |

| LiteReality: Graphics-Ready 3D Scene Reconstruction from RGB-D Scans |
|---|
| Zhening Huang, Xiaoyang Wu, Fangcheng Zhong, Hengshuang Zhao, Matthias Nießner, Joan Lasenby |
| NeurIPS 2025 |
| LiteReality is an automatic pipeline that converts RGB-D scans of indoor environments into graphics-ready scenes. In these scenes, all objects are represented as high-quality meshes with PBR materials that match their real-world appearance. The scenes also include articulated objects and are ready to integrate into graphics pipelines for rendering and physics-based interactions. |
| [video][bibtex][project page] |
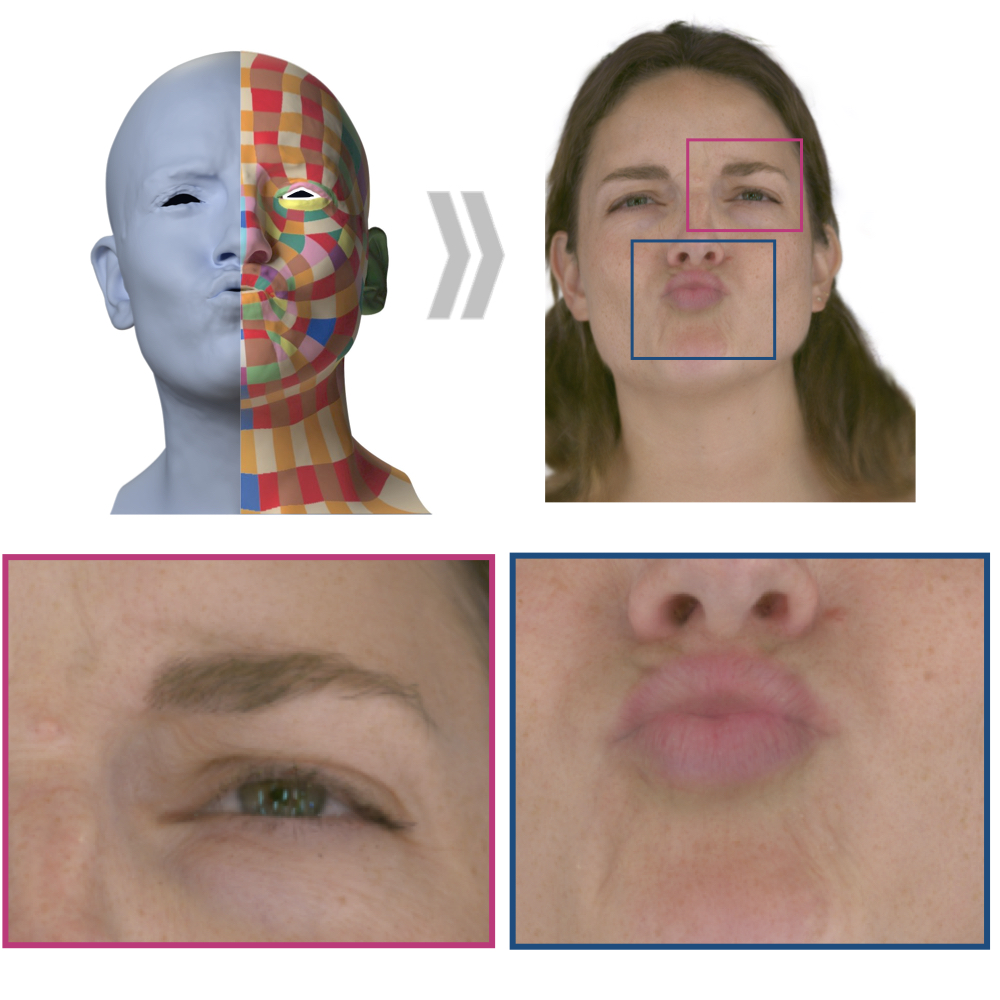
| ScaffoldAvatar: High-Fidelity Gaussian Avatars with Patch Expressions |
|---|
| Shivangi Aneja, Sebastian Weiss, Irene Baeza, Prashanth Chandran, Gaspard Zoss, Matthias Nießner, Derek Bradley |
| SIGGRAPH 2025 |
| ScaffoldAvatar presents a novel approach for reconstructing ultra-high fidelity animatable head avatars, which can be rendered in real-time. Our method operates on patch-based local expression features and synthesizes 3D Gaussians dynamically by leveraging tiny scaffold MLPs. We employ color-based densification and progressive training to obtain high-quality results and fast convergence. |
| [video][bibtex][project page] |
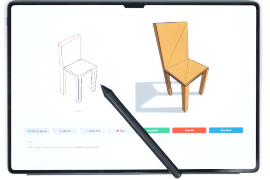
| MeshPad: Interactive Sketch-Conditioned Artist-Designed Mesh Generation and Editing |
|---|
| Haoxuan Li, Ziya Erkoç, Lei Li, Daniele Sirigatti, Vladislav Rosov, Angela Dai, Matthias Nießner |
| ICCV 2025 |
| MeshPad is a generative system for creating and editing 3D triangle meshes from sketch inputs. Designed for interactive workflows, it allows users to iteratively delete and add mesh parts through simple sketch edits. MeshPad uses a Transformer-based triangle sequence model with fast speculative prediction, achieving significantly better accuracy and user preference than prior methods. |
| [video][bibtex][project page] |

| SHeaP: Self-Supervised Head Geometry Predictor Learned via 2D Gaussians |
|---|
| Liam Schoneveld, Zhe Chen, Davide Davoli, Jiapeng Tang, Saimon Terazawa, Ko Nishino, Matthias Nießner |
| ICCV 2025 |
| SHeaP learns a state-of-the-art, real-time head geometry predictor through self-supervised learning on only 2D videos. The key idea is to use 2D Gaussian Splatting instead of mesh rasterization when computing the photometric reconstruction loss. |
| [video][bibtex][project page] |
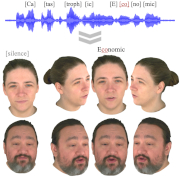
| GaussianSpeech: Audio-Driven Gaussian Avatars |
|---|
| Shivangi Aneja, Artem Sevastopolsky, Tobias Kirschstein, Justus Thies, Angela Dai, Matthias Nießner |
| ICCV 2025 |
| GaussianSpeech synthesizes high-fidelity animation sequences of photo-realistic, personalized 3D human head avatars from spoken audio. Our method can generate realistic and high-quality animations, including mouth interiors such as teeth, wrinkles, and specularities in the eyes. We handle diverse facial geometry, including hair buns and mustaches/beards, while effectively generalizing to in-the-wild audio clips. |
| [video][bibtex][project page] |

| QuickSplat: Fast 3D Surface Reconstruction via Learned Gaussian Initialization |
|---|
| Yueh-Cheng Liu, Lukas Höllein, Matthias Nießner, Angela Dai |
| ICCV 2025 |
| QuickSplat learns data-driven priors to generate dense initializations for 2D gaussian splatting optimization of large-scale indoor scenes. This provides a strong starting point for the reconstruction, which accelerates the convergence of the optimization and improves the geometry of flat wall structures. It further learns to jointly estimate the densification and update of the scene parameters iteratively, accelerating runtime and reducing depth errors. |
| [video][bibtex][project page] |
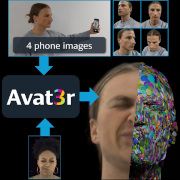
| Avat3r: Large Animatable Gaussian Reconstruction Model for High-fidelity 3D Head Avatars |
|---|
| Tobias Kirschstein, Javier Romero, Artem Sevastopolsky, Matthias Nießner, Shunsuke Saito |
| ICCV 2025 |
| Avat3r takes 4 input images of a person’s face and generates an animatable 3D head avatar in a single forward pass. The resulting 3D head representation can be animated at interactive rates. The entire creation process of the 3D avatar, from taking 4 smartphone pictures to the final result, can be executed within minutes. |
| [video][bibtex][project page] |

| Zero-shot Inexact CAD Model Alignment from a Single Image |
|---|
| Pattaramanee Arsomngern, Sasikarn Khwanmuang, Matthias Nießner, Supasorn Suwajanakorn |
| ICCV 2025 |
| Our approach infers the 3D scene structure from a single image, retrieves a 3D model from a database which it closely matches, and aligns it with the corresponding object in the image. |
| [video][bibtex][project page] |
| 3DGS-LM: Faster Gaussian-Splatting Optimization with Levenberg-Marquardt |
|---|
| Lukas Höllein, Aljaž Božič, Michael Zollhöfer, Matthias Nießner |
| ICCV 2025 |
| 3DGS-LM accelerates Gaussian-Splatting optimization by replacing the ADAM optimizer with Levenberg-Marquardt. We propose a highly-efficient GPU parallization scheme for PCG and implement it in custom CUDA kernels that compute Jacobian-vector products. |
| [video][bibtex][project page] |
| LT3SD: Latent Trees for 3D Scene Diffusion |
|---|
| Quan Meng, Lei Li, Matthias Nießner, Angela Dai |
| CVPR 2025 |
| We introduce LT3SD, a novel latent 3D scene diffusion approach enabling high-fidelity generation of infinite 3D environments in a patch-by-patch and coarse-to-fine fashion. |
| [video][bibtex][project page] |

| GAF: Gaussian Avatar Reconstruction from Monocular Videos via Multi-view Diffusion |
|---|
| Jiapeng Tang, Davide Davoli, Tobias Kirschstein, Liam Schoneveld, Matthias Nießner |
| CVPR 2025 |
| Given a short, monocular video captured by a commodity device such as a smartphone, GAF reconstructs a 3D Gaussian head avatar, which can be re-animated and rendered into photo-realistic novel views. Our key idea is to distill the reconstruction constraints from a multi-view head diffusion model in order to extrapolate to unobserved views and expressions. |
| [video][code][bibtex][project page] |

| PrEditor3D: Fast and Precise 3D Shape Editing |
|---|
| Ziya Erkoç, Can Gümeli, Chaoyang Wang, Matthias Nießner, Angela Dai, Peter Wonka, Hsin-Ying Lee, Peiye Zhuang |
| CVPR 2025 |
| We propose a training-free approach to 3D editing that enables the editing of a single shape within a few minutes. The edited 3D mesh aligns well with the prompts, and remains identical for regions that are not intended to be altered. Extensive experiments demonstrate the superiority of our method over previous approaches, enabling fast, high-quality editing while preserving unintended regions. |
| [video][bibtex][project page] |

| HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs |
|---|
| Artem Sevastopolsky, Philip Grassal, Simon Giebenhain, ShahRukh Athar, Luisa Verdoliva, Matthias Nießner |
| 3DV 2025 |
| We learn to generate large displacements for parametric head models, such as long hair, with high level of detail. The displacements can be added to an arbitrary head for animation and semantic editing. |
| [code][bibtex][project page] |
2024

| Coherent 3D Scene Diffusion From a Single RGB Image |
|---|
| Manuel Dahnert, Angela Dai, Norman Müller, Matthias Nießner |
| NeurIPS 2024 |
| We propose a novel diffusion-based method for 3D scene reconstruction from a single RGB image, leveraging an image-conditioned 3D scene diffusion model to denoise object poses and geometries. By learning a generative scene prior that captures inter-object relationships, our approach ensures consistent and accurate reconstructions. |
| [bibtex][project page] |

| L3DG: Latent 3D Gaussian Diffusion |
|---|
| Barbara Rössle, Norman Müller, Lorenzo Porzi, Samuel Rota Bulò, Peter Kontschieder, Angela Dai, Matthias Nießner |
| SIGGRAPH Asia 2024 |
| L3DG proposes generative modeling of 3D Gaussians using a learned latent space. This substantially reduces the complexity of the costly diffusion generation process, allowing higher detail on object-level generation, and scalability to room-scale scenes. |
| [video][bibtex][project page] |

| GGHead: Fast and Generalizable 3D Gaussian Heads |
|---|
| Tobias Kirschstein, Simon Giebenhain, Jiapeng Tang, Markos Georgopoulos, Matthias Nießner |
| SIGGRAPH Asia 2024 |
| GGHead generates photo-realistic 3D heads and renders them at 1k resolution in real-time. Thanks to the efficiency of 3D Gaussian Splatting, no 2D super-resolution network is needed anymore which hampered the view-consistency of prior work. We adopt a 3D GAN formulation which allows training GGHead solely from 2D image datasets. |
| [video][code][bibtex][project page] |
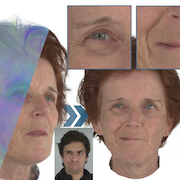
| NPGA: Neural Parametric Gaussian Avatars |
|---|
| Simon Giebenhain, Tobias Kirschstein, Martin Rünz, Lourdes Agapito, Matthias Nießner |
| SIGGRAPH Asia 2024 |
| NPGA is a method to create 3d avatars from multi-view video recordings which can be precisely animated using the expression space of the underlying neural parametric head model. For increased dynamic representational capacity, we leaverage per-Gaussian latent features, which are used to condition our deformation MLP. |
| [video][bibtex][project page] |
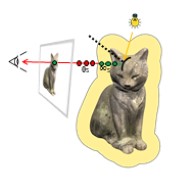
| Mesh2NeRF: Direct Mesh Supervision for Neural Radiance Field Representation and Generation |
|---|
| Yujin Chen, Yinyu Nie, Benjamin Ummenhofer, Reiner Birkl, Michael Paulitsch, Matthias Müller, Matthias Nießner |
| ECCV 2024 |
| Mesh2NeRF is a method for extracting ground truth radiance fields directly from 3D textured meshes by incorporating mesh geometry, texture, and environment lighting information. Mesh2NeRF serves as direct 3D supervision for neural radiance fields, leveraging mesh data for improving novel view synthesis performance. Mesh2NeRF can function as supervision for generative models during training on mesh collections. |
| [video][bibtex][project page] |

| Zero-Shot Detection of AI-Generated Images |
|---|
| Davide Cozzolino, Giovanni Poggi, Matthias Nießner, Luisa Verdoliva |
| ECCV 2024 (Oral) |
| New generative architectures emerge daily, requiring frequent updates to supervised detectors for synthetic images. To address this challenge, we propose a Zero-shot Entropy-based Detector (ZED) that neither needs AI-generated training data nor relies on knowledge of generative architectures to artificially synthesize their artifacts. The idea is to measure how surprising the image under analysis is compared to a model of real images. To this end, ZED leverages the intrinsic model of real images learned by a lossless image coder. |
| [bibtex][project page] |

| Fast Training of Diffusion Transformer with Extreme Masking for 3D Point Clouds Generation |
|---|
| Shentong Mo, Enze Xie, Yue Wu, Junsong Chen, Matthias Nießner, Zhenguo Li |
| ECCV 2024 |
| We propose FastDiT-3D, a novel masked diffusion transformer tailored for efficient 3D point cloud generation, which greatly reduces training costs. Our FastDiT-3D utilizes the encoder blocks with 3D global attention and Mixture-of-Experts (MoE) FFN to take masked voxelized point clouds as input. |
| [bibtex][project page] |

| LightIt: Illumination Modeling and Control for Diffusion Models |
|---|
| Peter Kocsis, Julien Philip, Kalyan Sunkavalli, Matthias Nießner, Yannick Hold-Geoffroy |
| CVPR 2024 |
| Recent generative methods lack lighting control, which is crucial to numerous artistic aspects. We propose to condition the generation on shading and normal maps. We model the lighting with single bounce shading, which includes cast shadows. We first train a shading estimation module to generate a dataset of real-world images and shading pairs. Then, we train a control network using the estimated shading and normals as input. |
| [video][bibtex][project page] |

| DiffusionAvatars: Deferred Diffusion for High-fidelity 3D Head Avatars |
|---|
| Tobias Kirschstein, Simon Giebenhain, Matthias Nießner |
| CVPR 2024 |
| DiffusionAvatar uses diffusion-based, deferred neural rendering to translate geometric cues from an underlying neural parametric head model (NPHM) to photo-realistic renderings. The underlying NPHM provides accurate control over facial expressions, while the deferred neural rendering leverages the 2D prior of StableDiffusion, in order to generate compelling images. |
| [video][code][bibtex][project page] |

| MonoNPHM: Dynamic Head Reconstruction from Monoculuar Videos |
|---|
| Simon Giebenhain, Tobias Kirschstein, Markos Georgopoulos, Martin Rünz, Lourdes Agapito, Matthias Nießner |
| CVPR 2024 |
| MonoNPHM is a neural parametric head model that disentangles geomery, appearance and facial expression into three separate latent spaces. Using MonoNPHM as a prior, we tackle the task of dynamic 3D head reconstruction from monocular RGB videos, using inverse, SDF-based, volumetric rendering. |
| [video][bibtex][project page] |

| Intrinsic Image Diffusion for Single-view Material Estimation |
|---|
| Peter Kocsis, Vincent Sitzmann, Matthias Nießner |
| CVPR 2024 |
| Appearance decomposition is an ambiguous task and collecting real data is challenging. We utilize a pre-trained diffusion model and formulate the problem probabilistically. We fine-tune a pre-trained diffusion model conditioned on a single input image to adapt its image prior to the prediction of albedo, roughness and metallic maps. With our sharp material predictions, we optimize for spatially-varying lighting to enable photo-realistic material editing and relighting. |
| [video][bibtex][project page] |

| ViewDiff: 3D-Consistent Image Generation with Text-to-Image Models |
|---|
| Lukas Höllein, Aljaž Božič, Norman Müller, David Novotny, Hung-Yu Tseng, Christian Richardt, Michael Zollhöfer, Matthias Nießner |
| CVPR 2024 |
| ViewDiff generates high-quality, multi-view consistent images of a real-world 3D object in authentic surroundings. We turn pretrained text-to-image model into 3D consistent image generator by finetuning them with multi-view supervision. |
| [video][bibtex][project page] |

| FaceTalk: Audio-Driven Motion Diffusion for Neural Parametric Head Models |
|---|
| Shivangi Aneja, Justus Thies, Angela Dai, Matthias Nießner |
| CVPR 2024 |
| Given an input audio signal, FaceTalk proposes a diffusion-based approach to synthesize high-quality and temporally consistent 3D motion sequences of high-fidelity human heads as neural parametric head models. FaceTalk can generate detailed facial expressions including wrinkles and eye blinks alongside temporally synchronized mouth movements for diverse audio inputs including songs and foreign languages. |
| [video][bibtex][project page] |

| SceneTex: High-Quality Texture Synthesis for Indoor Scenes via Diffusion Priors |
|---|
| Dave Zhenyu Chen, Haoxuan Li, Hsin-Ying Lee, Sergey Tulyakov, Matthias Nießner |
| CVPR 2024 |
| We propose SceneTex, a novel method for effectively generating high-quality and style-consistent textures for indoor scenes using depth-to-image diffusion priors. At its core, SceneTex proposes a multiresolution texture field to implicitly encode the mesh appearance. To further secure the style consistency across views, we introduce a cross-attention decoder to predict the RGB values by cross-attending to the pre-sampled reference locations in each instance. |
| [video][bibtex][project page] |
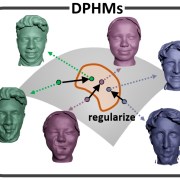
| DPHMs: Diffusion Parametric Head Models for Depth-based Tracking |
|---|
| Jiapeng Tang, Angela Dai, Yinyu Nie, Lev Markhasin, Justus Thies, Matthias Nießner |
| CVPR 2024 |
| We introduce Diffusion Parametric Head Models (DPHMs), a generative model that enables robust volumetric head reconstruction and tracking from monocular depth sequences. Tracking and reconstructing heads from real-world single-view depth sequences is very challenging, as the fitting to partial and noisy observations is underconstrained. To tackle these challenges, we propose a latent diffusion-based prior to regularize volumetric head reconstruction and tracking. This prior-based regularizer effectively constrains the identity and expression codes to lie on the underlying latent manifold which represents plausible head shapes. |
| [video][code][bibtex][project page] |

| DiffuScene: Denoising Diffusion Models for Generative Indoor Scene Synthesis |
|---|
| Jiapeng Tang, Yinyu Nie, Lev Markhasin, Angela Dai, Justus Thies, Matthias Nießner |
| CVPR 2024 |
| We present DiffuScene for indoor 3D scene synthesis based on a novel scene configuration denoising diffusion model. It generates 3D instance properties stored in an unordered object set and retrieves the most similar geometry for each object configuration, which is characterized as a concatenation of different attributes, including location, size, orientation, semantics, and geometry features. We introduce a diffusion network to synthesize a collection of 3D indoor objects by denoising a set of unordered object attributes. |
| [video][code][bibtex][project page] |
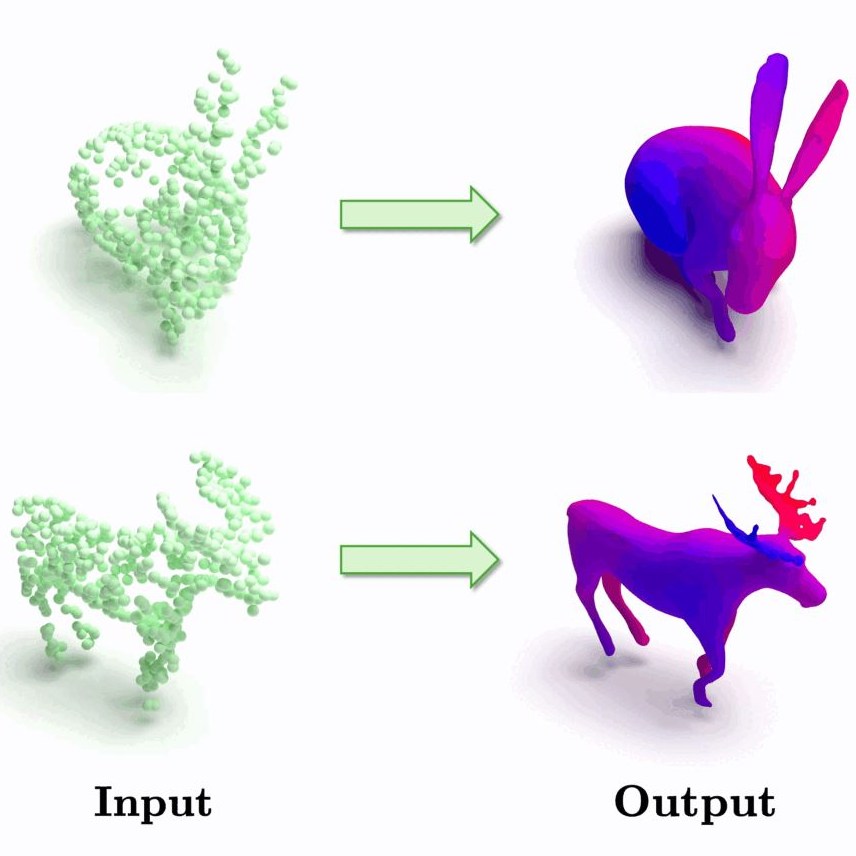
| Motion2VecSets: 4D Latent Vector Set Diffusion for Non-rigid Shape Reconstruction and Tracking |
|---|
| Wei Cao, Chang Luo, Biao Zhang, Matthias Nießner, Jiapeng Tang |
| CVPR 2024 |
| We introduce Motion2VecSets, a 4D diffusion model for dynamic surface reconstruction from point cloud sequences. We introduce a diffusion model that explicitly learns the shape and motion distribution of non-rigid objects through an iterative denoising process of compressed latent representations. We parameterize 4D dynamics with latent vector sets instead of using a global latent. This novel 4D representation allows us to learn local surface shape and deformation patterns, leading to more accurate non-linear motion capture and significantly improving generalizability to unseen motions and identities. |
| [video][bibtex][project page] |

| GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians |
|---|
| Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, Matthias Nießner |
| CVPR 2024 |
| We introduce GaussianAvatars, a new method to create photorealistic head avatars that are fully controllable in terms of expression, pose, and viewpoint. The core idea is a dynamic 3D representation based on 3D Gaussian splats that are rigged to a parametric morphable face model. This combination facilitates photorealistic rendering while allowing for precise animation control via the underlying parametric model. |
| [video][bibtex][project page] |

| MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers |
|---|
| Yawar Siddiqui, Antonio Alliegro, Alexey Artemov, Tatiana Tommasi, Daniele Sirigatti, Vladislav Rosov, Angela Dai, Matthias Nießner |
| CVPR 2024 |
| MeshGPT creates triangle meshes by autoregressively sampling from a transformer model that has been trained to produce tokens from a learned geometric vocabulary. Our method generates clean, coherent, and compact meshes, characterized by sharp edges and high fidelity. |
| [video][bibtex][project page] |

| TriPlaneNet: An Encoder for EG3D Inversion |
|---|
| Ananta Bhattarai, Matthias Nießner, Artem Sevastopolsky |
| WACV 2024 |
| EG3D is a powerful {z, camera}->image generative model, but inverting EG3D (finding a corresponding z for a given image) is not always trivial. We propose a fully-convolutional encoder for EG3D based on the observation that predicting both z code and tri-planes is beneficial. TriPlaneNet also works for videos and close to real time. |
| [video][code][bibtex][project page] |
2023

| GANeRF: Leveraging Discriminators to Optimize Neural Radiance Fields |
|---|
| Barbara Rössle, Norman Müller, Lorenzo Porzi, Samuel Rota Bulò, Peter Kontschieder, Matthias Nießner |
| SIGGRAPH Asia 2023 |
| GANeRF proposes an adversarial formulation whose gradients provide feedback for a 3D-consistent neural radiance field representation. This introduces additional constraints that enable more realistic novel view synthesis. |
| [video][bibtex][project page] |

| Text2Tex: Text-driven Texture Synthesis via Diffusion Models |
|---|
| Dave Zhenyu Chen, Yawar Siddiqui, Hsin-Ying Lee, Sergey Tulyakov, Matthias Nießner |
| ICCV 2023 |
| We present Text2Tex, a novel method for generating high-quality textures for 3D meshes from the given text prompts. Our method incorporates inpainting into a pre-trained depth-aware image diffusion model to progressively synthesize high resolution partial textures from multiple viewpoints. Furthermore, we propose an automatic view sequence generation scheme to determine the next best view for updating the partial texture. |
| [video][bibtex][project page] |

| ScanNet++: A High-Fidelity Dataset of 3D Indoor Scenes |
|---|
| Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, Angela Dai |
| ICCV 2023 |
| We present ScanNet++, a large scale dataset with 450+ 3D indoor scenes containing sub-millimeter resolution laser scans, registered 33-megapixel DSLR images, and commodity RGB-D streams from iPhone. The 3D reconstructions are annotated with long-tail and label-ambiguous semantics to benchmark semantic understanding methods, while the coupled DSLR and iPhone captures enable benchmarking of novel view synthesis methods in high-quality and commodity settings. |
| [video][bibtex][project page] |
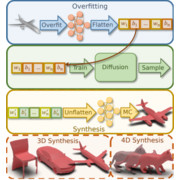
| HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion |
|---|
| Ziya Erkoç, Fangchang Ma, Qi Shan, Matthias Nießner, Angela Dai |
| ICCV 2023 |
| We propose HyperDiffusion, a novel approach for unconditional generative modeling of implicit neural fields. HyperDiffusion operates directly on MLP weights and generates new neural implicit fields encoded by synthesized MLP parameters. It enables diffusion modeling over a implicit, compact, and yet high-fidelity representation of complex signals across 3D shapes and 4D mesh animations within one single unified framework. |
| [video][bibtex][project page] |

| Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models |
|---|
| Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, Matthias Nießner |
| ICCV 2023 |
| Text2Room generates textured 3D meshes from a given text prompt using 2D text-to-image models. The core idea of our approach is a tailored viewpoint selection such that the content of each image can be fused into a seamless, textured 3D mesh. More specifically, we propose a continuous alignment strategy that iteratively fuses scene frames with the existing geometry. |
| [video][bibtex][project page] |
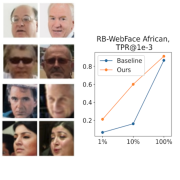
| How to Boost Face Recognition with StyleGAN? |
|---|
| Artem Sevastopolsky, Yury Malkov, Nikita Durasov, Luisa Verdoliva, Matthias Nießner |
| ICCV 2023 |
| State-of-the-art face recognition systems require huge amounts of labeled training data which is often compiled as a limited collection of celebrities images. We learn how to leverage pretraining of StyleGAN and an encoder for it on large-scale collections of random face images. The procedure can be applied to various backbones and is the most helpful on limited data. We release the collected datasets AfricanFaceSet-5M and AsianFaceSet-3M and a new fairness-concerned testing benchmark RB-WebFace. |
| [video][code][bibtex][project page] |
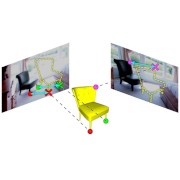
| CAD-Estate: Large-scale CAD Model Annotation in RGB Videos |
|---|
| Kevis-Kokitsi Maninis, Stefan Popov, Matthias Nießner, Vittorio Ferrari |
| ICCV 2023 |
| We propose a method for annotating videos of complex multi-object scenes with a globally-consistent 3D representation of the objects. This semi-automatic method allows for large scale crowd-sourcing and has allowed us to construct a large-scale dataset by annotating 21K real-estate videos from YouTube with 108K object instances of 12K unique CAD models. |
| [bibtex][project page] |

| UniT3D: A Unified Transformer for 3D Dense Captioning and Visual Grounding |
|---|
| Dave Zhenyu Chen, Ronghang Hu, Xinlei Chen, Matthias Nießner, Angel X. Chang |
| ICCV 2023 |
| We propose UniT3D, a simple yet effective fully unified transformer-based architecture for jointly solving 3D visual grounding and dense captioning. UniT3D enables learning a strong multimodal representation across the two tasks through a supervised joint pre-training scheme with bidirectional and seq-to-seq objectives. |
| [bibtex][project page] |
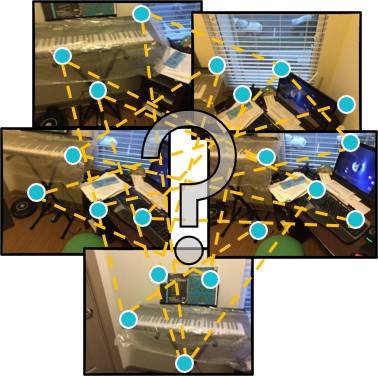
| End2End Multi-View Feature Matching with Differentiable Pose Optimization |
|---|
| Barbara Rössle, Matthias Nießner |
| ICCV 2023 |
| End2End Multi-View Feature Matching connects feature matching and pose optimization in an end-to-end trainable approach that enables matches and confidences to be informed by the pose estimation objective. We introduce GNN-based multi-view matching to predict matches and confidences tailored to a differentiable pose solver, which significantly improves pose estimation performance. |
| [video][bibtex][project page] |

| NeRSemble: Multi-view Radiance Field Reconstruction of Human Heads |
|---|
| Tobias Kirschstein, Shenhan Qian, Simon Giebenhain, Tim Walter, Matthias Nießner |
| SIGGRAPH'23 |
| We propose NeRSemble for high-quality novel view synthesis of human heads. We combine a deformation field modeling coarse motion with an ensemble of multi-resolution hash encodings to represent fine expression-dependent details. To train our model, we recorded a novel multi-view video dataset containing over 4700 sequences of human heads covering a variety of facial expressions. |
| [video][code][bibtex][project page] |
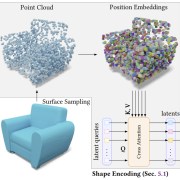
| 3DShape2VecSet: A 3D Shape Representation for Neural Fields and Generative Diffusion Models |
|---|
| Biao Zhang, Jiapeng Tang, Matthias Nießner, Peter Wonka |
| SIGGRAPH'23 |
| We introduce 3DShape2VecSet, a novel shape representation for neural fields designed for generative diffusion models. Our new representation encodes neural fields on top of a set of vectors. |
| [video][code][bibtex][project page] |
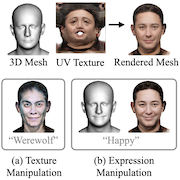
| ClipFace: Text-guided Editing of Textured 3D Morphable Models |
|---|
| Shivangi Aneja, Justus Thies, Angela Dai, Matthias Nießner |
| SIGGRAPH'23 |
| ClipFace learns a self-supervised generative model for jointly synthesizing geometry and texture leveraging 3D morphable face models, that can be guided by text prompts. For a given 3D mesh with fixed topology, we can generate arbitrary face textures as UV maps. The textured mesh can then be manipulated with text guidance to generate diverse set of textures and geometric expressions in 3D by altering (a) only the UV texture maps for Texture Manipulation and (b) both UV maps and mesh geometry for Expression Manipulation. |
| [video][bibtex][project page] |

| HumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion |
|---|
| Mustafa Işık, Martin Rünz, Markos Georgopoulos, Taras Khakhulin, Jonathan Starck, Lourdes Agapito, Matthias Nießner |
| SIGGRAPH'23 |
| We introduce ActorsHQ, a novel multi-view dataset that provides 12MP footage from 160 cameras for 16 sequences with high-fidelity per frame mesh reconstructions. We demonstrate challenges that emerge from using such high-resolution data and show that our newly-introduced HumanRF effectively leverages this data, making a significant step towards production-level quality novel view synthesis. |
| [video][bibtex][project page] |
| Mask3D: Pre-training 2D Vision Transformers by Learning Masked 3D Priors |
|---|
| Ji Hou, Xiaoliang Dai, Zijian He, Angela Dai, Matthias Nießner |
| CVPR 2023 |
| Mask3D is a noval approach that embeds 3D structural priors into 2D learned feature representations by leveraging existing large-scale RGB-D data in a self-supervised pre-training. The experiments show that Mask3D outperforms state-of-the-art 3D pre-training on various image understanding tasks, with a significant improvement of +6.5% mIoU on ScanNet image semantic segmentation. |
| [video][bibtex][project page] |
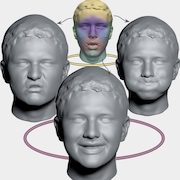
| Learning Neural Parametric Head Models |
|---|
| Simon Giebenhain, Tobias Kirschstein, Markos Georgopoulos, Martin Rünz, Lourdes Agapito, Matthias Nießner |
| CVPR 2023 |
| We present Neural Parametric Head Models (NPHMs) for high fidelity representation of complete human heads. We utilize a hybrid representation for a person's canonical head geometry, which is deformed using a deformation field to model expressions. To train our model we captured a large dataset of high-end laser scans of 120 persons in 20 expressions each. |
| [video][bibtex][project page] |

| Panoptic Lifting for 3D Scene Understanding with Neural Fields |
|---|
| Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bulo, Norman Müller, Matthias Nießner, Angela Dai, Peter Kontschieder |
| CVPR 2023 |
| Given only RGB images of an in-the-wild scene as input, Panoptic Lifting optimizes a panoptic radiance field which can be queried for color, depth, semantics, and instances for any point in space. |
| [bibtex][project page] |
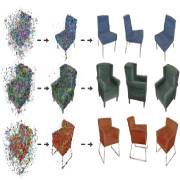
| DiffRF: Rendering-guided 3D Radiance Field Diffusion |
|---|
| Norman Müller, Yawar Siddiqui, Lorenzo Porzi, Samuel Rota Bulo, Peter Kontschieder, Matthias Nießner |
| CVPR 2023 |
| DiffRF is a denoising diffusion probabilistic model directly operating on 3D radiance fields and trained with an additional volumetric rendering loss. This enables learning strong radiance priors with high rendering quality and accurate geometry. This appraoch naturally enables tasks like 3D masked completion or image-to-volume synthesis. |
| [video][bibtex][project page] |

| High-Res Facial Appearance Capture from Polarized Smartphone Images |
|---|
| Dejan Azinović, Olivier Maury, Christophe Hery, Matthias Nießner, Justus Thies |
| CVPR 2023 |
| We propose a novel method for high-quality facial texture reconstruction from RGB images using a novel capturing routine based on a single smartphone which we equip with an inexpensive polarization foil. Specifically, we turn the flashlight into a polarized light source and add a polarization filter on top of the camera to separate the skin's diffuse and specular response. |
| [video][bibtex][project page] |

| ObjectMatch: Robust Registration using Canonical Object Correspondences |
|---|
| Can Gümeli, Angela Dai, Matthias Nießner |
| CVPR 2023 |
| ObjectMatch leverages indirect correspondences obtained via semantic object identification. For instance, when an object is seen from the front in one frame and from the back in another frame, ObjectMatch provides additional pose constraints through canonical object correspondences. We first propose a neural network to predict such correspondences, which we then combine in our energy formulation with state-of-the-art keypoint matching solved with a joint Gauss-Newton optimization. Our method significantly improves state-of-the-art feature matching in low-overlap frame pairs as well as in the registration of low frame-rate SLAM sequences. |
| [video][bibtex][project page] |
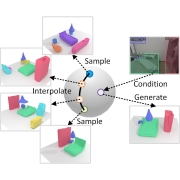
| Learning 3D Scene Priors with 2D Supervision |
|---|
| Yinyu Nie, Angela Dai, Xiaoguang Han, Matthias Nießner |
| CVPR 2023 |
| We learn 3D scene priors with 2D supervision. We model a latent hypersphere surface to represent a manifold of 3D scenes, characterizing the semantic and geometric distribution of objects in 3D scenes. This supports many downstream applications, including scene synthesis, interpolation and single-view reconstruction. |
| [video][bibtex][project page] |

| COSMOS: Catching Out-of-Context Misinformation with Self-Supervised Learning |
|---|
| Shivangi Aneja, Chris Bregler, Matthias Nießner |
| AAAI 2023 |
| Despite the recent attention to DeepFakes, one of the most prevalent ways to mislead audiences on social media is the use of unaltered images in a new but false context. To address these challenges and support fact-checkers, we propose a new method that automatically detects out-of-context image and text pairs. Our key insight is to leverage grounding of image with text to distinguish out-of-context scenarios that cannot be disambiguated with language alone. Check out the paper for more details. |
| [video][code][bibtex][project page] |
2022
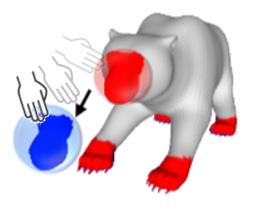
| Neural Shape Deformation Priors |
|---|
| Jiapeng Tang, Lev Markhasin, Bi Wang, Justus Thies, Matthias Nießner |
| NeurIPS 2022 |
| We present Neural Shape Deformation Priors, a novel method for shape manipulation that predicts mesh deformations of non-rigid objects from user-provided handle movements. We learn the geometry-aware deformation behavior from a large-scale dataset containing a diverse set of non-rigid deformations. We introduce transformer-based deformation networks that represent a shape deformation as a composition of local surface deformations. |
| [video][code][bibtex][project page] |

| 3DILG: Irregular Latent Grids for 3D Generative Modeling |
|---|
| Biao Zhang, Matthias Nießner, Peter Wonka |
| NeurIPS 2022 |
| We proposed a method for representing shapes as irregular latent grids. This representation enables 3d generative modeling with autoregressive transformers. We show different applications that improve over the current state of the art. All probabilistic experiments confirm that we are able to generate detailed and high quality shapes to yield the new state of the art in generative 3D shape modeling. |
| [code][bibtex][project page] |
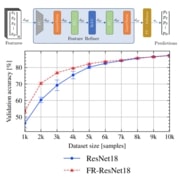
| The Unreasonable Effectiveness of Fully-Connected Layers for Low-Data Regimes |
|---|
| Peter Kocsis, Peter Sukenik, Guillem Braso, Matthias Nießner, Laura Leal-Taixé, Ismail Elezi |
| NeurIPS 2022 |
| We show that adding fully-connected layers is beneficial for the generalization of convolutional networks in the tasks working in the low-data regime. Furthermore, we present a novel online joint knowledge distillation method (OJKD), which allows us to utilize additional final fully-connected layers during training but drop them during inference without a noticeable loss in performance. Doing so, we keep the same number of weights during test time. |
| [code][bibtex][project page] |

| Texturify: Generating Textures on 3D Shape Surfaces |
|---|
| Yawar Siddiqui, Justus Thies, Fangchang Ma, Qi Shan, Matthias Nießner, Angela Dai |
| ECCV 2022 |
| Texturify learns to generate geometry-aware textures for untextured collections of 3D objects. Our method trains from only a collection of images and a collection of untextured shapes, which are both often available, without requiring any explicit 3D color supervision or shape-image correspondence. Textures are created directly on the surface of a given 3D shape, enabling generation of high-quality, compelling textured 3D shapes. |
| [bibtex][project page] |
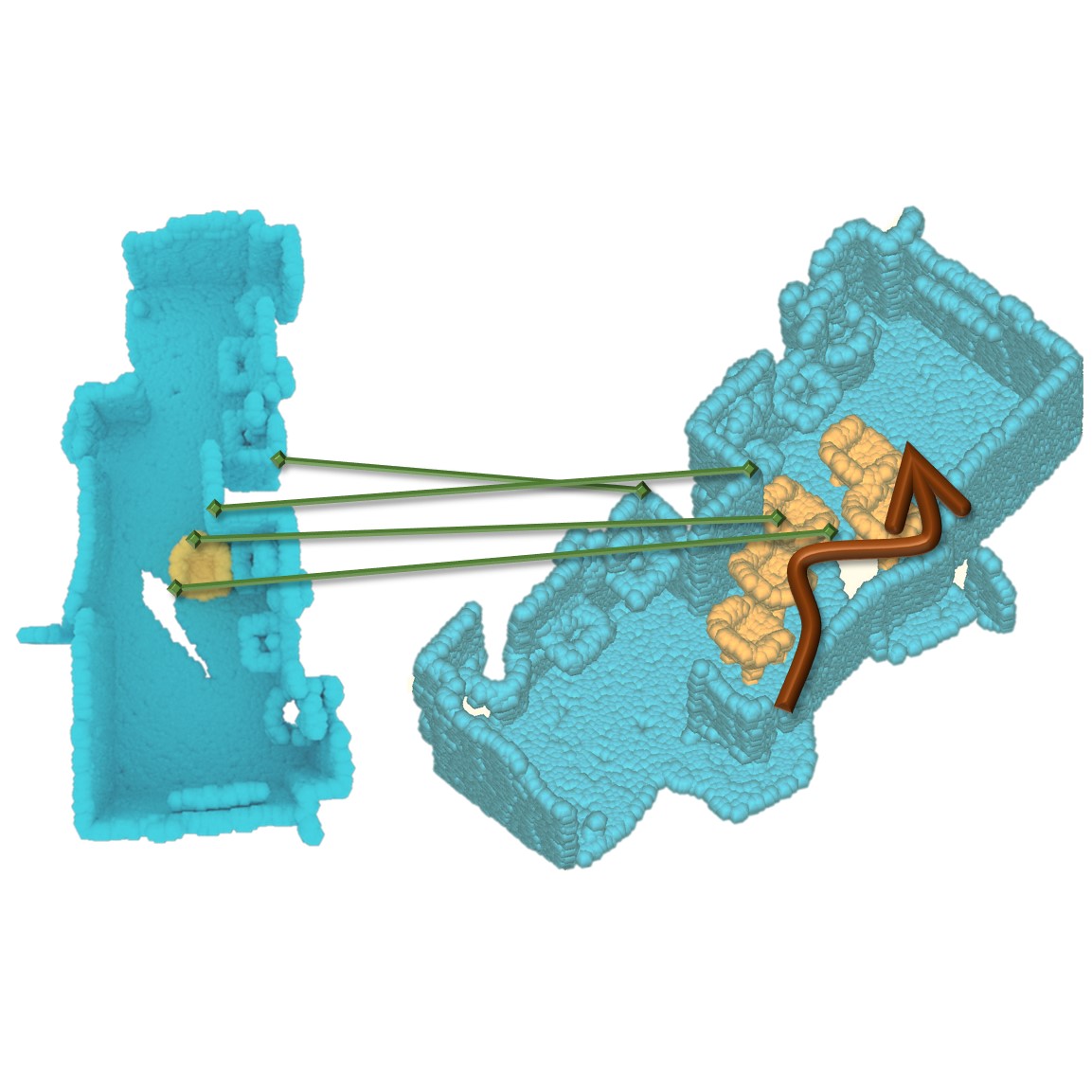
| 4DContrast: Contrastive Learning with Dynamic Correspondences for 3D Scene Understanding |
|---|
| Yujin Chen, Matthias Nießner, Angela Dai |
| ECCV 2022 |
| We present a new approach to instill 4D dynamic object priors into learned 3D representations by unsupervised pre-training. We propose a new data augmentation scheme leveraging synthetic 3D shapes moving in static 3D environments, and employ contrastive learning under 3D-4D constraints that encode 4D invariances into the learned 3D representations. Experiments demonstrate that our unsupervised representation learning results in improvement in downstream 3D semantic segmentation, object detection, and instance segmentation tasks. |
| [video][bibtex][project page] |

| TAFIM: Targeted Adversarial Attacks against Facial Image Manipulations |
|---|
| Shivangi Aneja, Lev Markhasin, Matthias Nießner |
| ECCV 2022 |
| We introduce a novel data-driven approach that produces image-specific perturbations which are embedded in the original images to prevent face manipulation by causing the manipulation model to produce a predefined manipulation target. Compared to traditional adversarial attack baselines that optimize noise patterns for each image individually, our generalized model only needs a single forward pass, thus running orders of magnitude faster and allowing for easy integration in image processing stacks, even on resource-constrained devices like smartphones. Check out the paper for more details. |
| [video][code][bibtex][project page] |
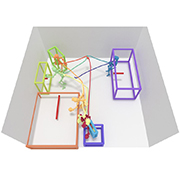
| Pose2Room: Understanding 3D Scenes from Human Activities |
|---|
| Yinyu Nie, Angela Dai, Xiaoguang Han, Matthias Nießner |
| ECCV 2022 |
| From an observed pose trajectory of a person performing daily activities in an indoor scene, we learn to estimate likely object configurations of the scene underlying these interactions, as set of object class labels and oriented 3D bounding boxes. By sampling from our probabilistic decoder, we synthesize multiple plausible object arrangements. |
| [video][bibtex][project page] |
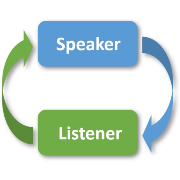
| D3Net: A Speaker-Listener Architecture for Semi-supervised Dense Captioning and Visual Grounding in RGB-D Scans |
|---|
| Dave Zhenyu Chen, Qirui Wu, Matthias Nießner, Angel X. Chang |
| ECCV 2022 |
| We present D3Net, an end-to-end neural speaker-listener architecture that can detect, describe and discriminate. Our D3Net unifies dense captioning and visual grounding in 3D in a self-critical manner. This self-critical property of D3Net also introduces discriminability during object caption generation and enables semi-supervised training on ScanNet data with partially annotated descriptions. |
| [video][bibtex][project page] |
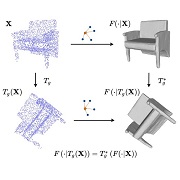
| 3D Equivariant Graph Implicit Functions |
|---|
| Yunlu Chen, Basura Fernando, Hakan Bilen, Matthias Nießner, Efstratios Gavves |
| ECCV 2022 |
| We propose a novel family of graph-based 3D implicit representations. The non-Euclidean graph embeddings in multiple-scales enable modeling of high-fidelity 3D geometric details and facilitate inherent robustness against geometric transformations. We further incorporate equivariant graph layers for guaranteed generalization to unseen similarity transformations, including rotation, translation, and scaling. |
| [video][bibtex][project page] |
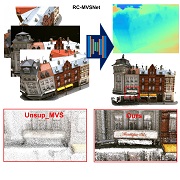
| RC-MVSNet: Unsupervised Multi-View Stereo with Neural Rendering |
|---|
| Di Chang, Aljaž Božič, Tong Zhang, Qingsong Yan, Yingcong Chen, Sabine Süsstrunk, Matthias Nießner |
| ECCV 2022 |
| We introduce RC-MVSNet, a neural-rendering based unsupervised Multi-View Stereo 3D reconstruction approach. First, we leverage NeRF-like rendering to generate consistent photometric supervision for non-Lambertian surfaces in unsupervised MVS task. Second, we impose depth rendering consistency loss to refine the initial depth map predicted by naive photometric consistency loss. We also propose Gaussian-Uniform sampling to improve NeRF's ability to learn the geometry features close to the object surface, which overcomes occlusion artifacts present in existing approaches. |
| [code][bibtex][project page] |

| Advances in Neural Rendering |
|---|
| Ayush Tewari, Justus Thies, Ben Mildenhall, Pratul P. Srinivasan, Edgar Tretschk, Yifan Wang, Christoph Lassner, Vincent Sitzmann, Ricardo Martin-Brualla, Stephen Lombardi, Tomas Simon, Christian Theobalt, Matthias Nießner, Jonathan T. Barron, Gordon Wetzstein, Michael Zollhöfer, Vladislav Golyanik |
| Eurographics 2022 |
| In this state-of-the-art report, we analyze these recent developments in Neural Rendering in detail and review essential related work. We explain, compare, and critically analyze the common underlying algorithmic concepts that enabled these recent advancements. |
| [bibtex][project page] |

| AutoRF: Learning 3D Object Radiance Fields from Single View Observations |
|---|
| Norman Müller, Andrea Simonelli, Lorenzo Porzi, Samuel Rota Bulò, Matthias Nießner, Peter Kontschieder |
| CVPR 2022 |
| From just a single view, we learn neural 3D object representations for free novel view synthesis. This setting is in stark contrast to the majority of existing works that leverage multiple views of the same object, employ explicit priors during training, or require pixel-perfect annotations. Our method decouples object geometry, appearance, and pose enabling generalization to unseen objects, even across different datasets of challenging real-world street scenes such as nuScenes, KITTI, and Mapillary Metropolis. |
| [video][bibtex][project page] |

| Neural Head Avatars from Monocular RGB Videos |
|---|
| Philip-William Grassal, Malte Prinzler, Titus Leistner, Carsten Rother, Matthias Nießner, Justus Thies |
| CVPR 2022 |
| We present Neural Head Avatars, a novel neural representation that explicitly models the surface geometry and appearance of an animatable human avatar that can be used for teleconferencing in AR/VR or other applications in the movie or games industry that rely on a digital human. |
| [video][bibtex][project page] |

| ROCA: Robust CAD Model Retrieval and Alignment from a Single Image |
|---|
| Can Gümeli, Angela Dai, Matthias Nießner |
| CVPR 2022 |
| We present ROCA, a novel end-to-end approach that retrieves and aligns 3D CAD models to a single RGB image using a shape database. Thus, our method enables 3D understanding of an observed scene using clean and compact CAD representations of objects. Core to our approach is our differentiable alignment optimization based on dense 2D-3D object correspondences and Procrustes alignment. |
| [video][code][bibtex][project page] |

| Neural RGB-D Surface Reconstruction |
|---|
| Dejan Azinović, Ricardo Martin-Brualla, Dan B Goldman, Matthias Nießner, Justus Thies |
| CVPR 2022 |
| In this work, we explore how to leverage the success of implicit novel view synthesis methods for surface reconstruction. We demonstrate how depth measurements can be incorporated into the radiance field formulation to produce more detailed and complete reconstruction results than using methods based on either color or depth data alone. |
| [video][bibtex][project page] |

| StyleMesh: Style Transfer for Indoor 3D Scene Reconstructions |
|---|
| Lukas Höllein, Justin Johnson, Matthias Nießner |
| CVPR 2022 |
| We apply style transfer on mesh reconstructions of indoor scenes. We optimize an explicit texture for the reconstructed mesh of a scene and stylize it jointly from all available input images. Our depth- and angle-aware optimization leverages surface normal and depth data of the underlying mesh to create a uniform and consistent stylization for the whole scene. |
| [video][bibtex][project page] |

| Dense Depth Priors for Neural Radiance Fields from Sparse Input Views |
|---|
| Barbara Rössle, Jonathan T. Barron, Ben Mildenhall, Pratul P. Srinivasan, Matthias Nießner |
| CVPR 2022 |
| We leverage dense depth priors for recovering neural radiance fields (NeRF) of complete rooms when only a handful of input images are available. First, we take advantage of the sparse depth that is freely available from the structure from motion preprocessing. Second, we use depth completion to convert these sparse points into dense depth maps and uncertainty estimates, which are used to guide NeRF optimization. |
| [video][bibtex][project page] |
2021

| Panoptic 3D Scene Reconstruction From a Single RGB Image |
|---|
| Manuel Dahnert, Ji Hou, Matthias Nießner, Angela Dai |
| NeurIPS 2021 |
| Panoptic 3D Scene Reconstruction combines the tasks of 3D reconstruction, semantic segmentation and instance segmentation. From a single RGB image we predict 2D information and lift these into a sparse volumetric 3D grid, where we predict geometry, semantic labels and 3D instance labels. |
| [video][code][bibtex][project page] |

| TransformerFusion: Monocular RGB Scene Reconstruction using Transformers |
|---|
| Aljaž Božič, Pablo Palafox, Justus Thies, Angela Dai, Matthias Nießner |
| NeurIPS 2021 |
| We introduce TransformerFusion, a transformer-based 3D scene reconstruction approach. The input monocular RGB video frames are fused into a volumetric feature representation of the scene by a transformer network that learns to attend to the most relevant image observations, resulting in an accurate online surface reconstruction. |
| [video][bibtex][project page] |

| NPMs: Neural Parametric Models for 3D Deformable Shapes |
|---|
| Pablo Palafox, Aljaž Božič, Justus Thies, Matthias Nießner, Angela Dai |
| ICCV 2021 |
| We propose Neural Parametric Models (NPMs), a learned alternative to traditional, parametric 3D models. 4D dynamics are disentangled into latent-space representations of shape and pose, leveraging the flexibility of recent developments in learned implicit functions. Once learned, NPMs enable optimization over the learned spaces to fit to new observations. |
| [video][code][bibtex][project page] |

| 4DComplete: Non-Rigid Motion Estimation Beyond the Observable Surface |
|---|
| Yang Li, Hikari Takehara, Takafumi Taketomi, Bo Zheng, Matthias Nießner |
| ICCV 2021 |
| We introduce 4DComplete, the first method that jointly recovers the shape and motion field from partial observations. We also provide a large-scale non-rigid 4D dataset for training and benchmaring. It consists of 1,972 animation sequences, and 122,365 frames. |
| [video][code][bibtex][project page] |
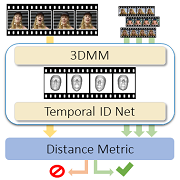
| ID-Reveal: Identity-aware DeepFake Video Detection |
|---|
| Davide Cozzolino, Andreas Rössler, Justus Thies, Matthias Nießner, Luisa Verdoliva |
| ICCV 2021 |
| ID-Reveal is an identity-aware DeepFake video detection. Based on reference videos of a person, we estimate a temporal embedding which is used as a distance metric to detect fake videos. |
| [video][code][bibtex][project page] |

| RetrievalFuse: Neural 3D Scene Reconstruction with a Database |
|---|
| Yawar Siddiqui, Justus Thies, Fangchang Ma, Qi Shan, Matthias Nießner, Angela Dai |
| ICCV 2021 |
| We introduce a new 3D reconstruction method that directly leverages scene geometry from the training database, facilitating transfer of coherent structures and local detail from train scene geometry. |
| [video][code][bibtex][project page] |
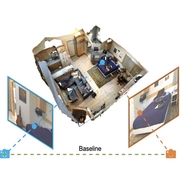
| Pri3D: Can 3D Priors Help 2D Representation Learning? |
|---|
| Ji Hou, Saining Xie, Benjamin Graham, Angela Dai, Matthias Nießner |
| ICCV 2021 |
| Pri3D leverages 3D priors for downstream 2D image understanding tasks: during pre-training, we incorporate view-invariant and geometric priors from color-geometry information given by RGB-D datasets, imbuing geometric priors into learned features. We show that these 3D-imbued learned features can effectively transfer to improved performance on 2D tasks such as semantic segmentation, object detection, and instance segmentation. |
| [video][code][bibtex][project page] |

| Dynamic Surface Function Networks for Clothed Human Bodies |
|---|
| Andrei Burov, Matthias Nießner, Justus Thies |
| ICCV 2021 |
| We present a novel method for temporal coherent reconstruction and tracking of clothed humans. Given a monocular RGB-D sequence, we learn a person-specific body model which is based on a dynamic surface function network. To this end, we explicitly model the surface of the person using a multi-layer perceptron (MLP) which is embedded into the canonical space of the SMPL body model. |
| [video][bibtex][project page] |

| Thallo — Scheduling for High-Performance Large-scale Non-linear Least-Squares Solvers |
|---|
| Michael Mara, Felix Heide, Michael Zollhöfer, Matthias Nießner, Pat Hanrahan |
| ACM Transactions on Graphics 2021 (TOG) |
| Thallo is a high-performance domain-specific language (DSL) that generates tailored high-performance GPU solvers and schedules from a concise, high-level energy description without the hassle of manually constructing and maintaining tedious and error-prone solvers. |
| [bibtex][project page] |

| Dynamic Neural Radiance Fields for Monocular 4D Facial Avatar Reconstruction |
|---|
| Guy Gafni, Justus Thies, Michael Zollhöfer, Matthias Nießner |
| CVPR 2021 (Oral) |
| Given a monocular portrait video sequence of a person, we reconstruct a dynamic neural radiance field representing a 4D facial avatar. The radiance field is conditioned on blendshape expressions, which allow us to then photorealistically synthesize novel head poses as well as novel facial expressions of the person. This can be used for self-reenactment, novel view synthesis and cross-subject reenactment. |
| [video][code][bibtex][project page] |

| SPSG: Self-Supervised Photometric Scene Generation from RGB-D Scans |
|---|
| Angela Dai, Yawar Siddiqui, Justus Thies, Julien Valentin, Matthias Nießner |
| CVPR 2021 |
| We present SPSG, a novel approach to generate high-quality, colored 3D models of scenes from RGB-D scan observations by learning to infer unobserved scene geometry and color in a self-supervised fashion. Rather than relying on 3D reconstruction losses to inform our 3D geometry and color reconstruction, we propose adversarial and perceptual losses operating on 2D renderings in order to achieve high-resolution, high-quality colored reconstructions of scenes. |
| [video][code][bibtex][project page] |

| Seeing Behind Objects for 3D Multi-Object Tracking in RGB-D Sequences |
|---|
| Norman Müller, Yu-Shiang Wong, Niloy J. Mitra, Angela Dai, Matthias Nießner |
| CVPR 2021 |
| We introduce a novel method to jointly predict complete geometry and dense correspondences of rigidly moving objects for 3D multi-object tracking on RGB-D sequences. By hallucinating unseen regions of objects, we can obtain additional correspondences between the same instance, thus providing robust tracking even under strong change of appearance. |
| [video][bibtex][project page] |
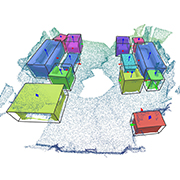
| RfD-Net: Point Scene Understanding by Semantic Instance Reconstruction |
|---|
| Yinyu Nie, Ji Hou, Xiaoguang Han, Matthias Nießner |
| CVPR 2021 |
| We introduce RfD-Net that jointly detects and reconstructs dense object surfaces from raw point clouds. It leverages the sparsity of point cloud data and focuses on predicting shapes that are recognized with high objectness. It not only eases the difficulty of learning 2-D manifold surfaces from sparse 3D space, the point clouds in each object proposal convey shape details that support implicit function learning to reconstruct any high-resolution surfaces. |
| [video][code][bibtex][project page] |

| Exploring Data-Efficient 3D Scene Understanding with Contrastive Scene Contexts |
|---|
| Ji Hou, Benjamin Graham, Matthias Nießner, Saining Xie |
| CVPR 2021 (Oral) |
| Our study reveals that exhaustive labelling of 3D point clouds might be unnecessary; and remarkably, on ScanNet, even using 0.1% of point labels, we still achieve 89% (instance segmentation) and 96% (semantic segmentation) of the baseline performance that uses full annotations. |
| [video][bibtex][project page] |

| Scan2Cap: Context-aware Dense Captioning in RGB-D Scans |
|---|
| Dave Zhenyu Chen, Ali Gholami, Matthias Nießner, Angel X. Chang |
| CVPR 2021 |
| We introduce the new task of dense captioning in RGB-D scans with a model that can densely localize objects in a 3D scene and describe them using natural language in a single forward pass. |
| [video][code][bibtex][project page] |

| Neural Deformation Graphs for Globally-consistent Non-rigid Reconstruction |
|---|
| Aljaž Božič, Pablo Palafox, Michael Zollhöfer, Justus Thies, Angela Dai, Matthias Nießner |
| CVPR 2021 (Oral) |
| We introduce Neural Deformation Graphs for globally-consistent deformation tracking and 3D reconstruction of non-rigid objects. Specifically, we implicitly model a deformation graph via a deep neural network and empose per-frame viewpoint consistency as well as inter-frame graph and surface consistency constraints in a self-supervised fashion. |
| [video][bibtex][project page] |
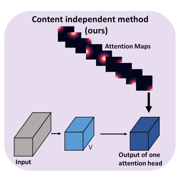
| Explicitly Modeled Attention Maps for Image Classification |
|---|
| Andong Tan, Duc Tam Nguyen, Maximilian Dax, Matthias Nießner, Thomas Brox |
| AAAI 2021 |
| We propose a novel self-attention module that explicitly models attention-maps to mitigate the problem of high computational requirements of attention maps. Our evaluation shows that our method achieves an accuracy improvement of up to 2.2% over the ResNet-baselines in ImageNet ILSVRC and outperforms other self-attention methods such as AA-ResNet152 (Bello et al., 2019) in accuracy by 0.9% with 6.4% fewer parameters and 6.7% fewer GFLOPs. |
| [bibtex][project page] |

| RigidFusion: RGB-D Scene Reconstruction with Rigidly-moving Objects |
|---|
| Yu-Shiang Wong, Changjian Li, Matthias Nießner, Niloy J. Mitra |
| Eurographics 2021 |
| We present RigidFusion, a novel surface reconstruction approach that handles changing environments. This is achieved by an asynchronous moving-object detection method, combined with a modified volumetric fusion. |
| [video][bibtex][project page] |
2020

| Neural Non Rigid Tracking |
|---|
| Aljaž Božič, Pablo Palafox, Michael Zollhöfer, Angela Dai, Justus Thies, Matthias Nießner |
| NeurIPS 2020 |
| We introduce a novel, end-to-end learnable, differentiable non-rigid tracker that enables state-of-the-art non-rigid reconstruction. By enabling gradient back-propagation through a non-rigid as-rigid-as-possible optimization solver, we are able to learn correspondences in an end-to-end manner such that they are optimal for the task of non-rigid tracking |
| [video][bibtex][project page] |

| Egocentric Videoconferencing |
|---|
| Mohamed Elgharib, Mohit Mendiratta, Justus Thies, Matthias Nießner, Hans-Peter Seidel, Ayush Tewari, Vladislav Golyanik, Christian Theobalt |
| ACM Transactions on Graphics 2020 (TOG) |
| We introduce a method for egocentric videoconferencing that enables hands-free video calls, for instance by people wearing smart glasses or other mixed-reality devices. |
| [bibtex][project page] |
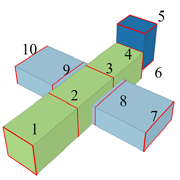
| Modeling 3D Shapes by Reinforcement Learning |
|---|
| Cheng Lin, Tingxiang Fan, Wenping Wang, Matthias Nießner |
| ECCV 2020 |
| We explore how to enable machines to model 3D shapes like human modelers using deep reinforcement learning (RL). |
| [video][code][bibtex][project page] |

| SceneCAD: Predicting Object Alignments and Layouts in RGB-D Scans |
|---|
| Armen Avetisyan, Tatiana Khanova, Christopher Choy, Denver Dash, Angela Dai, Matthias Nießner |
| ECCV 2020 |
| We present a novel approach to reconstructing lightweight, CAD-based representations of scanned 3D environments from commodity RGB-D sensors. |
| [code][bibtex][project page] |
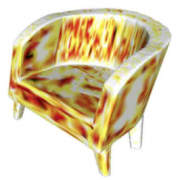
| CAD-Deform: Deformable Fitting of CAD Models to 3D Scans |
|---|
| Vladislav Ishimtsev, Alexey Bokhovkin, Alexey Artemov, Savva Ignatiev, Matthias Nießner, Denis Zorin, Evgeny Burnaev |
| ECCV 2020 |
| We propose CAD-Deform, a method which obtains more accurate CAD-to-scan fits by non-rigidly deforming retrieved CAD models. |
| [code][bibtex][project page] |

| ScanRefer: 3D Object Localization in RGB-D Scans using Natural Language |
|---|
| Dave Zhenyu Chen, Angel X. Chang, Matthias Nießner |
| ECCV 2020 |
| We propose ScanRefer, a method that learns a fused descriptor from 3D object proposals and encoded sentence embeddings, to address the newly introduced task of 3D object localization in RGB-D scans using natural language descriptions. Along with the method we release a large-scale dataset of 51,583 descriptions of 11,046 objects from 800 ScanNet scenes. |
| [video][code][bibtex][project page] |

| Neural Voice Puppetry: Audio-driven Facial Reenactment |
|---|
| Justus Thies, Mohamed Elgharib, Ayush Tewari, Christian Theobalt, Matthias Nießner |
| ECCV 2020 |
| Given an audio sequence of a source person or digital assistant, we generate a photo-realistic output video of a target person that is in sync with the audio of the source input. |
| [video][code][bibtex][project page] |

| State of the Art on Neural Rendering |
|---|
| Ayush Tewari, Ohad Fried, Justus Thies, Vincent Sitzmann, Stephen Lombardi, Kalyan Sunkavalli, Ricardo Martin-Brualla, Tomas Simon, Jason Saragih, Matthias Nießner, Rohit K Pandey, Sean Fanello, Gordon Wetzstein, Jun-Yan Zhu, Christian Theobalt, Maneesh Agrawala, Eli Shechtman, Dan B Goldman, Michael Zollhöfer |
| EG 2020 |
| Neural rendering is a new and rapidly emerging field that combines generative machine learning techniques with physical knowledge from computer graphics, e.g., by the integration of differentiable rendering into network training. This state-of-the-art report summarizes the recent trends and applications of neural rendering. |
| [bibtex][project page] |
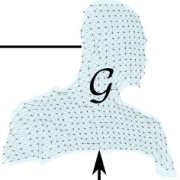
| Learning to Optimize Non-Rigid Tracking |
|---|
| Yang Li, Aljaž Božič, Tianwei Zhang, Yanli Ji, Tatsuya Harada, Matthias Nießner |
| CVPR 2020 (Oral) |
| We learn the tracking of non-rigid objects by differentiating through the underlying non-rigid solver. Specifically, we propose ConditionNet which learns to generate a problem-specific preconditioner using a large number of training samples from the Gauss-Newton update equation. The learned preconditioner increases PCG’s convergence speed by a significant margin. |
| [bibtex][project page] |

| 3D-MPA: Multi Proposal Aggregation for 3D Semantic Instance Segmentation |
|---|
| Francis Engelmann, Martin Bokeloh, Alireza Fathi, Bastian Leibe, Matthias Nießner |
| CVPR 2020 |
| We present 3D-MPA, a method for instance segmentation on 3D point clouds. We show that grouping proposals improves over NMS and outperforms previous state-of-the-art methods on the tasks of 3D object detection and semantic instance segmentation on the ScanNetV2 benchmark and the S3DIS dataset. |
| [video][bibtex][project page] |

| DeepDeform: Learning Non-rigid RGB-D Reconstruction with Semi-supervised Data |
|---|
| Aljaž Božič, Michael Zollhöfer, Christian Theobalt, Matthias Nießner |
| CVPR 2020 |
| We present a large dataset of 400 scenes, over 390,000 RGB-D frames, and 5,533 densely aligned frame pairs, and introduce a data-driven non-rigid RGB-D reconstruction approach using learned heatmap correspondences, achieving state-of-the-art reconstruction results on a newly established quantitative benchmark. |
| [video][code][bibtex][project page] |

| Local Implicit Grid Representations for 3D Scenes |
|---|
| Chiyu 'Max' Jiang, Avneesh Sud, Ameesh Makadia, Jingwei Huang, Matthias Nießner, Thomas Funkhouser |
| CVPR 2020 |
| We learned implicit representations for large 3D environments anchored in regular grids, which facilitates high-quality surface reconstruction from unstructured input point clouds. |
| [video][code][bibtex][project page] |

| Adversarial Texture Optimization from RGB-D Scans |
|---|
| Jingwei Huang, Justus Thies, Angela Dai, Abhijit Kundu, Chiyu 'Max' Jiang, Leonidas Guibas, Matthias Nießner, Thomas Funkhouser |
| CVPR 2020 |
| We present a novel approach for color texture generation using a conditional adversarial loss obtained from weakly-supervised views. Specifically, we propose an approach to produce photorealistic textures for approximate surfaces, even from misaligned images, by learning an objective function that is robust to these errors. |
| [video][bibtex][project page] |
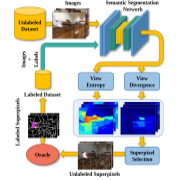
| ViewAL: Active Learning with Viewpoint Entropy for Semantic Segmentation |
|---|
| Yawar Siddiqui, Julien Valentin, Matthias Nießner |
| CVPR 2020 |
| We propose ViewAL, a novel active learning strategy for semantic segmentation that exploits viewpoint consistency in multi-view datasets. |
| [video][code][bibtex][project page] |

| SG-NN: Sparse Generative Neural Networks for Self-Supervised Scene Completion of RGB-D Scans |
|---|
| Angela Dai, Christian Diller, Matthias Nießner |
| CVPR 2020 |
| We present a novel approach that converts partial and noisy RGB-D scans into high-quality 3D scene reconstructions by inferring unobserved scene geometry. Our approach is fully self-supervised and can hence be trained solely on real-world, incomplete scans. |
| [video][code][bibtex][project page] |
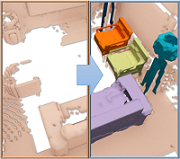
| RevealNet: Seeing Behind Objects in RGB-D Scans |
|---|
| Ji Hou, Angela Dai, Matthias Nießner |
| CVPR 2020 |
| This paper introduces the task of semantic instance completion: from an incomplete, RGB-D scan of a scene, we detect the individual object instances comprising the scene and jointly infer their complete object geometry. |
| [bibtex][project page] |

| Image-guided Neural Object Rendering |
|---|
| Justus Thies, Michael Zollhöfer, Christian Theobalt, Marc Stamminger, Matthias Nießner |
| ICLR 2020 |
| We propose a new learning-based novel view synthesis approach for scanned objects that is trained based on a set of multi-view images, where we directly train a deep neural network to synthesize a view-dependent image of an object. |
| [video][bibtex][project page] |
2019

| RIO: 3D Object Instance Re-Localization in Changing Indoor Environments |
|---|
| Johanna Wald, Armen Avetisyan, Nassir Navab, Federico Tombari, Matthias Nießner |
| ICCV 2019 (Oral) |
| In this work, we explore the task of 3D object instance re-localization (RIO): given one or multiple objects in an RGB-D scan, we want to estimate their corresponding 6DoF poses in another 3D scan of the same environment taken at a later point in time. |
| [video][bibtex][project page] |
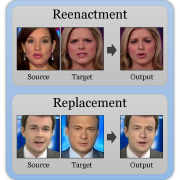
| FaceForensics++: Learning to Detect Manipulated Facial Images |
|---|
| Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Nießner |
| ICCV 2019 |
| In this paper, we examine the realism of state-of-the-art facial image manipulation methods, and how difficult it is to detect them - either automatically or by humans. In particular, we create a datasets that is focused on DeepFakes, Face2Face, FaceSwap, and Neural Textures as prominent representatives for facial manipulations. |
| [video][code][bibtex][project page] |

| End-to-End CAD Model Retrieval and 9DoF Alignment in 3D Scans |
|---|
| Armen Avetisyan, Angela Dai, Matthias Nießner |
| ICCV 2019 |
| We present a novel, end-to-end approach to align CAD models to an 3D scan of a scene, enabling transformation of a noisy, incomplete 3D scan to a compact, CAD reconstruction with clean, complete object geometry. |
| [bibtex][project page] |

| Joint Embedding of 3D Scan and CAD Objects |
|---|
| Manuel Dahnert, Angela Dai, Leonidas Guibas, Matthias Nießner |
| ICCV 2019 |
| In this paper, we address the problem of cross-domain retrieval between partial, incomplete 3D scan objects and complete CAD models. To this end, we learn a joint embedding where semantically similar objects from both domains lie close together regardless of low-level differences, such as clutter or noise. To enable fine-grained evaluation of scan-CAD model retrieval we additionally present a new dataset of scan-CAD object similarity annotations. |
| [video][bibtex][project page] |

| DDSL: Deep Differentiable Simplex Layer for Learning Geometric Signals |
|---|
| Chiyu 'Max' Jiang, Dana Lansigan, Philip Marcus, Matthias Nießner |
| ICCV 2019 |
| We present a Deep Differentiable Simplex Layer (DDSL) for neural networks for geometric deep learning. The DDSLis a differentiable layer compatible with deep neural net-works for bridging simplex mesh-based geometry represen-tations (point clouds, line mesh, triangular mesh, tetrahe-dral mesh) with raster images (e.g., 2D/3D grids). |
| [bibtex][project page] |

| Deferred Neural Rendering: Image Synthesis using Neural Textures |
|---|
| Justus Thies, Michael Zollhöfer, Matthias Nießner |
| ACM Transactions on Graphics 2019 (TOG) |
| We introduce Deferred Neural Rendering, a new paradigm for image synthesis that combines the traditional graphics pipeline with learnable components. Specifically, we propose Neural Textures, which are learned feature maps that are trained as part of the scene capture process. Similar to traditional textures, neural textures are stored as maps on top of 3D mesh proxies; however, the high-dimensional feature maps contain significantly more information, which can be interpreted by our new deferred neural rendering pipeline. Both neural textures and deferred neural renderer are trained end-to-end, enabling us to synthesize photo-realistic images even when the original 3D content was imperfect. |
| [video][bibtex][project page] |

| Multi-Robot Collaborative Dense Scene Reconstruction |
|---|
| Siyan Dong, Kai Xu, Qiang Zhou, Andrea Tagliasacchi, Shiqing Xin, Matthias Nießner, Baoquan Chen |
| ACM Transactions on Graphics 2019 (TOG) |
| We present an autonomous scanning approach which allows multiple robots to perform collaborative scanning for dense 3D reconstruction of unknown indoor scenes. Our method plans scanning paths for several robots, allowing them to efficiently coordinate with each other such that the collective scanning coverage and reconstruction quality is maximized while the overall scanning effort is minimized. |
| [video][bibtex][project page] |

| Face2Face: Real-time Face Capture and Reenactment of RGB Videos |
|---|
| Justus Thies, Michael Zollhöfer, Marc Stamminger, Christian Theobalt, Matthias Nießner |
| CACM 2019 (Research Highlight) |
| Research highlight of the Face2Face approach featured on the cover of Communications of the ACM in January 2019. Face2Face is an approach for real-time facial reenactment of a monocular target video. The method had significant impact in the research community and far beyond; it won several wards, e.g., Siggraph ETech Best in Show Award, it was featured in countless media articles, e.g., NYT, WSJ, Spiegel, etc., and it had a massive reach on social media with millions of views. The work was arguably started bringing attention to manipulations of facial videos. |
| [video][bibtex][project page] |
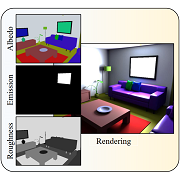
| Inverse Path Tracing for Joint Material and Lighting Estimation |
|---|
| Dejan Azinović, Tzu-Mao Li, Anton Kaplanyan, Matthias Nießner |
| CVPR 2019 (Oral) |
| We introduce Inverse Path Tracing, a novel approach to jointly estimate the material properties of objects and light sources in indoor scenes by using an invertible light transport simulation. |
| [video][bibtex][project page] |

| 3D-SIS: 3D Semantic Instance Segmentation of RGB-D Scans |
|---|
| Ji Hou, Angela Dai, Matthias Nießner |
| CVPR 2019 (Oral) |
| We introduce 3D-SIS, a novel neural network architecture for 3D semantic instance segmentation in commodity RGB-D scans. |
| [video][code][bibtex][project page] |

| Scan2CAD: Learning CAD Model Alignment in RGB-D Scans |
|---|
| Armen Avetisyan, Manuel Dahnert, Angela Dai, Angel X. Chang, Manolis Savva, Matthias Nießner |
| CVPR 2019 (Oral) |
| We present Scan2CAD, a novel data-driven method that learns to align clean 3D CAD models from a shape database to the noisy and incomplete geometry of a commodity RGB-D scan. |
| [video][code][bibtex][project page] |
| Scan2Mesh: From Unstructured Range Scans to 3D Meshes |
|---|
| Angela Dai, Matthias Nießner |
| CVPR 2019 |
| We introduce Scan2Mesh, a novel data-driven approach which introduces a generative neural network architecture for creating 3D meshes as indexed face sets, conditioned on an input partial scan. |
| [bibtex][project page] |

| DeepVoxels: Learning Persistent 3D Feature Embeddings |
|---|
| Vincent Sitzmann, Justus Thies, Felix Heide, Matthias Nießner, Gordon Wetzstein, Michael Zollhöfer |
| CVPR 2019 (Oral) |
| In this work, we address the lack of 3D understanding of generative neural networks by introducing a persistent 3D feature embedding for view synthesis. To this end, we propose DeepVoxels, a learned representation that encodes the view-dependent appearance of a 3D object without having to explicitly model its geometry. |
| [video][bibtex][project page] |
| TextureNet: Consistent Local Parametrizations for Learning from High-Resolution Signals on Meshes |
|---|
| Jingwei Huang, Haotian Zhang, Li Yi, Thomas Funkhouser, Matthias Nießner, Leonidas Guibas |
| CVPR 2019 (Oral) |
| We introduce, TextureNet, a neural network architecture designed to extract features from high-resolution signals associated with 3D surface meshes (e.g., color texture maps). The key idea is to utilize a 4-rotational symmetric (4-RoSy) field to define a domain for convolution on a surface. |
| [bibtex][project page] |
| Spherical CNNs on Unstructured Grids |
|---|
| Chiyu 'Max' Jiang, Jingwei Huang, Karthik Kashinath, Prabhat, Philip Marcus, Matthias Nießner |
| ICLR 2019 |
| We present an efficient convolution kernel for Convolutional Neural Networks (CNNs) on unstructured grids using parameterized differential operators while focusing on spherical signals such as panorama images or planetary signals. To this end, we replace conventional convolution kernels with linear combinations of differential operators that are weighted by learnable parameters. |
| [code][bibtex][project page] |
| Convolutional Neural Networks on non-uniform geometrical signals using Euclidean spectral transformation |
|---|
| Chiyu 'Max' Jiang, Dequan Wang, Jingwei Huang, Philip Marcus, Matthias Nießner |
| ICLR 2019 |
| We develop mathematical formulations for Non-Uniform Fourier Transforms (NUFT) to directly, and optimally, sample nonuniform data signals of different topologies defined on a simplex mesh into the spectral domain with no spatial sampling error. The spectral transform is performed in the Euclidean space, which removes the translation ambiguity from works on the graph spectrum. |
| [bibtex][project page] |
2018
| RegNet: Learning the Optimization of Direct Image-to-Image Pose Registration |
|---|
| Lei Han, Mengqi Ji, Lu Fang, Matthias Nießner |
| arXiv 2018 |
| In this paper, we demonstrate that the inaccurate numerical Jacobian limits the convergence range which could be improved greatly using learned approaches. Based on this observation, we propose a novel end-to-end network, RegNet, to learn the optimization of image-to-image pose registration. By jointly learning feature representation for each pixel and partial derivatives that replace handcrafted ones (e.g., numerical differentiation) in the optimization step, the neural network facilitates end-to-end optimization. |
| [bibtex][project page] |

| ForensicTransfer: Weakly-supervised Domain Adaptation for Forgery Detection |
|---|
| Davide Cozzolino, Justus Thies, Andreas Rössler, Christian Riess, Matthias Nießner, Luisa Verdoliva |
| arXiv 2018 |
| ForensicTransfer tackles two challenges in multimedia forensics. First, we devise a learning-based forensic detector which adapts well to new domains, i.e., novel manipulation methods. Second we handle scenarios where only a handful of fake examples are available during training. |
| [bibtex][project page] |

| FaceForensics: A Large-scale Video Dataset for Forgery Detection in Human Faces |
|---|
| Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Nießner |
| arXiv 2018 |
| In this paper, we introduce FaceForensics, a large scale video dataset consisting of 1004 videos with more than 500000 frames, altered with Face2Face, that can be used for forgery detection and to train generative refinement methods. |
| [video][bibtex][project page] |

| Calipso: Physics-based Image and Video Editing through CAD Model Proxies |
|---|
| Nazim Haouchine, Frederick Roy, Hadrien Courtecuisse, Matthias Nießner, Stephane Cotin |
| Visual Computer 2018 |
| We present Calipso, an interactive method for editing images and videos in a physically-coherent manner. Our main idea is to realize physics-based manipulations by running a full physics simulation on proxy geometries given by non-rigidly aligned CAD models. |
| [video][bibtex][project page] |

| Plan3D: Viewpoint and Trajectory Optimization for Aerial Multi-View Stereo Reconstruction |
|---|
| Benjamin Hepp, Matthias Nießner, Otmar Hilliges |
| ACM Transactions on Graphics 2018 (TOG) |
| We introduce a new method that efficiently computes a set of viewpoints and trajectories for high-quality 3D reconstructions in outdoor environments. Our goal is to automatically explore an unknown area, and obtain a complete 3D scan of a region of interest (e.g., a large building). |
| [bibtex][project page] |
| Parsing Geometry Using Structure-Aware Shape Templates |
|---|
| Vignesh Ganapathi-Subramanian, Olga Diamanti, Soeren Pirk, Chengcheng Tang, Matthias Nießner, Leonidas Guibas |
| 3DV 2018 |
| In this paper, we organize large shape collections into parameterized shape templates to capture the underlying structure of the objects. The templates allow us to transfer the structural information onto new objects and incomplete scans. |
| [video][bibtex][project page] |

| QuadriFlow: A Scalable and Robust Method for Quadrangulation |
|---|
| Jingwei Huang, Yichao Zhou, Matthias Nießner, Jonathan Richard Shewchuk, Leonidas Guibas |
| SGP 2018 (Best Paper Award) |
| QuadriFlow is a scalable algorithm for generating quadrilateral surface meshes based on the Instant Field-Aligned Meshes of Jakob et al.. We modify the original algorithm such that it efficiently produces meshes with many fewer singularities. Singularities in quadrilateral meshes cause problems for many applications, includ- ing parametrization and rendering with Catmull-Clark subdivision surfaces. |
| [code][bibtex][supplemental][project page] |
| 3DMV: Joint 3D-Multi-View Prediction for 3D Semantic Scene Segmentation |
|---|
| Angela Dai, Matthias Nießner |
| ECCV 2018 |
| We present 3DMV, a novel method for 3D semantic scene segmentation of RGB-D scans in indoor environments using a joint 3D-multi-view prediction network. In contrast to existing methods that either use geometry or RGB data as input for this task, we combine both data modalities in a joint, end-to-end network architecture. |
| [code][bibtex][project page] |

| PlaneMatch: Patch Coplanarity Prediction for Robust RGB-D Reconstruction |
|---|
| Yifei Shi, Kai Xu, Matthias Nießner, Szymon Rusinkiewicz, Thomas Funkhouser |
| ECCV 2018 (Oral) |
| We introduce a novel RGB-D patch descriptor designed for detecting coplanar surfaces in SLAM reconstruction. The core of our method is a deep convolutional neural net that takes in RGB, depth, and normal information of a planar patch in an image and outputs a descriptor that can be used to find coplanar patches from other images. |
| [bibtex][project page] |

| HeadOn: Real-time Reenactment of Human Portrait Videos |
|---|
| Justus Thies, Michael Zollhöfer, Marc Stamminger, Christian Theobalt, Matthias Nießner |
| ACM Transactions on Graphics 2018 (TOG) |
| We propose HeadOn, the first real-time source-to-target reenactment approach for complete human portrait videos that enables transfer of torso and head motion, face expression, and eye gaze. Given a short RGB-D video of the target actor, we automatically construct a personalized geometry proxy that embeds a parametric head, eye, and kinematic torso model. A novel real-time reenactment algorithm employs this proxy to photo-realistically map the captured motion from the source actor to the target actor. |
| [video][bibtex][project page] |

| FaceVR: Real-Time Facial Reenactment and Eye Gaze Control in Virtual Reality |
|---|
| Justus Thies, Michael Zollhöfer, Marc Stamminger, Christian Theobalt, Matthias Nießner |
| ACM Transactions on Graphics 2018 (TOG) |
| We propose FaceVR, a novel image-based method that enables video teleconferencing in VR based on self-reenactment. FaceVR enables VR teleconferencing using an image-based technique that results in nearly photo-realistic outputs. The key component of FaceVR is a robust algorithm to perform real-time facial motion capture of an actor who is wearing a head-mounted display (HMD). |
| [video][bibtex][project page] |

| Deep Video Portaits |
|---|
| Hyeongwoo Kim, Pablo Garrido, Ayush Tewari, Weipeng Xu, Justus Thies, Matthias Nießner, Patrick Pérez, Christian Richardt, Michael Zollhöfer, Christian Theobalt |
| ACM Transactions on Graphics 2018 (TOG) |
| Our novel approach enables photo-realistic re-animation of portrait videos using only an input video. The core of our approach is a generative neural network with a novel space-time architecture. The network takes as input synthetic renderings of a parametric face model, based on which it predicts photo-realistic video frames for a given target actor. |
| [video][bibtex][project page] |

| ScanComplete: Large-Scale Scene Completion and Semantic Segmentation for 3D Scans |
|---|
| Angela Dai, Daniel Ritchie, Martin Bokeloh, Scott Reed, Jürgen Sturm, Matthias Nießner |
| CVPR 2018 |
| We introduce ScanComplete, a novel data-driven approach for taking an incomplete 3D scan of a scene as input and predicting a complete 3D model along with per-voxel semantic labels. The key contribution of our method is its ability to handle large scenes with varying spatial extent, managing the cubic growth in data size as scene size increases. |
| [video][code][bibtex][project page] |

| State of the Art on Monocular 3D Face Reconstruction, Tracking, and Applications |
|---|
| Michael Zollhöfer, Justus Thies, Derek Bradley, Pablo Garrido, Thabo Beeler, Patrick Pérez, Marc Stamminger, Matthias Nießner, Christian Theobalt |
| Eurographics 2018 |
| This state-of-the-art report summarizes recent trends in monocular facial performance capture and discusses its applications, which range from performance-based animation to real-time facial reenactment. We focus our discussion on methods where the central task is to recover and track a three dimensional model of the human face using optimization-based reconstruction algorithms. |
| [bibtex][project page] |

| State of the Art on 3D Reconstruction with RGB-D Cameras |
|---|
| Michael Zollhöfer, Patrick Stotko, Andreas Görlitz, Christian Theobalt, Matthias Nießner, Reinhard Klein, Andreas Kolb |
| Eurographics 2018 |
| In this state-of-the-art report, we analyze these recent developments in RGB-D scene reconstruction in detail and review essential related work. We explain, compare, and critically analyze the common underlying algorithmic concepts that enabled these recent advancements. Furthermore, we show how algorithms are designed to best exploit the benefits of RGB-D data while suppressing their often non-trivial datadistortions. |
| [bibtex][project page] |
2017

| Matterport3D: Learning from RGB-D Data in Indoor Environments |
|---|
| Angel X. Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Nießner, Manolis Savva, Shuran Song, Andy Zeng, Yinda Zhang |
| 3DV 2017 |
| In this paper, we introduce Matterport3D, a large-scale RGB-D dataset containing 10,800 panoramic views from 194,400 RGB-D images of 90 building-scale scenes. |
| [bibtex][project page] |

| Multiframe Scene Flow with Piecewise Rigid Motion |
|---|
| Vladislav Golyanik, Kihwan Kim, Robert Maier, Matthias Nießner, Didier Stricker, Jan Kautz |
| 3DV 2017 |
| We introduce a novel multi-frame scene flow approach that jointly optimizes the consistency of the patch appearances and their local rigid motions from RGB-D image sequences. |
| [bibtex][project page] |

| 3DLite: Towards Commodity 3D Scanning for Content Creation |
|---|
| Jingwei Huang, Angela Dai, Leonidas Guibas, Matthias Nießner |
| ACM Transactions on Graphics 2017 (TOG) |
| We present 3DLite, a novel approach to reconstruct 3D environments using consumer RGB-D sensors, making a step towards directly utilizing captured 3D content in graphics applications, such as video games, VR, or AR. Rather than reconstructing an accurate one-to-one representation of the real world, our method computes a lightweight, low-polygonal geometric abstraction of the scanned geometry. |
| [video][bibtex][supplemental][project page] |
| Autonomous Reconstruction of Unknown Indoor Scenes Guided by Time-varying Tensor Fields |
|---|
| Kai Xu, Lintao Zheng, Zihao Yan, Guohang Yan, Eugene Zhang, Matthias Nießner, Oliver Deussen, Daniel Cohen-Or, Hui Huang |
| ACM Transactions on Graphics 2017 (TOG) |
| We present a navigation-by-reconstruction approach to address this question where moving paths of the robot are planned to account for both global efficiency for fast exploration and local smoothness to obtain high-quality scans. |
| [video][code][bibtex][project page] |

| Opt: A Domain Specific Language for Non-linear Least Squares Optimization in Graphics and Imaging |
|---|
| Zachary DeVito, Michael Mara, Michael Zollhöfer, Gilbert Bernstein, Jonathan Ragan-Kelley, Christian Theobalt, Pat Hanrahan, Matthew Fisher, Matthias Nießner |
| ACM Transactions on Graphics 2017 (TOG) |
| We propose a new language, Opt, in which a user simply writes energy functions over image- or graph-structured unknowns, and a compiler automatically generates state-of-the-art GPU optimization kernels. |
| [bibtex][project page] |

| BundleFusion: Real-time Globally Consistent 3D Reconstruction using On-the-fly Surface Re-integration |
|---|
| Angela Dai, Matthias Nießner, Michael Zollhöfer, Shahram Izadi, Christian Theobalt |
| ACM Transactions on Graphics 2017 (TOG) |
| We introduce a novel, real-time, end-to-end 3D reconstruction framework, with a robust pose optimization strategy based on sparse feature matches and dense geometric and photometric alignment. One main contribution is the ability to update the reconstructed model on-the-fly as new (global) pose optimization results become available. |
| [video][bibtex][project page] |

| Intrinsic3D: High-Quality 3D Reconstruction by Joint Appearance and Geometry Optimization with Spatially-Varying Lighting |
|---|
| Robert Maier, Kihwan Kim, Daniel Cremers, Jan Kautz, Matthias Nießner |
| ICCV 2017 |
| We introduce a novel method to obtain high-quality 3D reconstructions from consumer RGB-D sensors. Our core idea is to simultaneously optimize for geometry encoded in a signed distance field (SDF), textures from automaticallyselected keyframes, and their camera poses along with material and scene lighting. |
| [code][bibtex][supplemental][project page] |

| A Lightweight Approach for On-the-Fly Reflectance Estimation |
|---|
| Kihwan Kim, Jinwei Gu, Stephen Tyree, Pavlo Molchanov, Matthias Nießner, Jan Kautz |
| ICCV 2017 (Oral) |
| We propose a lightweight, learning-based approach for surface reflectance estimation directly from 8-bit RGB images in real-time, which can be easily plugged into any 3D scanning-and-fusion system with a commodity RGBD sensor. |
| [bibtex][project page] |

| ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes |
|---|
| Angela Dai, Angel X. Chang, Manolis Savva, Maciej Halber, Thomas Funkhouser, Matthias Nießner |
| CVPR 2017 (Spotlight) |
| We introduce ScanNet, an RGB-D video dataset containing 2.5M views in 1513 scenes annotated with 3D camera poses, surface reconstructions, and semantic segmentations. |
| [video][bibtex][project page] |

| Shape Completion using 3D-Encoder-Predictor CNNs and Shape Synthesis |
|---|
| Angela Dai, Charles Ruizhongtai Qi, Matthias Nießner |
| CVPR 2017 (Spotlight) |
| We introduce a data-driven approach to complete partial 3D shapes through a combination of volumetric deep neural networks and 3D shape synthesis. From a partially-scanned input shape, our method first infers a low-resolution - but complete - output. |
| [bibtex][project page] |

| 3DMatch: Learning the Matching of Local 3D Geometry in Range Scans |
|---|
| Andy Zeng, Shuran Song, Matthias Nießner, Matthew Fisher, Jianxiong Xiao |
| CVPR 2017 (Oral) |
| In this paper, we introduce 3DMatch, a data-driven local feature learner that jointly learns a geometric feature representation and an associated metric function from a large collection of real-world scanning data. |
| [video][bibtex][project page] |
2016

| Learning to Navigate the Energy Landscape |
|---|
| Julien Valentin, Angela Dai, Matthias Nießner, Pushmeet Kohli, Philip H. S. Torr, Shahram Izadi, Cem Keskin |
| 3DV 2016 |
| In this paper, we present a novel, general, and efficient architecture for addressing computer vision problems that are approached from an `Analysis by Synthesis' standpoint. |
| [video][bibtex][project page] |

| VolumeDeform: Real-time Volumetric Non-rigid Reconstruction |
|---|
| Matthias Innmann, Michael Zollhöfer, Matthias Nießner, Christian Theobalt, Marc Stamminger |
| ECCV 2016 |
| We present a novel approach for the reconstruction of dynamic geometric shapes using a single hand-held consumer-grade RGB-D sensor at real-time rates. Our method does not require a pre-defined shape template to start with and builds up the scene model from scratch during the scanning process. |
| [video][bibtex][supplemental][project page] |

| Efficient GPU Rendering of Subdivision Surfaces using Adaptive Quadtrees |
|---|
| Wade Brainerd, Tim Foley, Manuel Kraemer, Henry Moreton, Matthias Nießner |
| ACM Transactions on Graphics 2016 (TOG) |
| We present a novel method for real-time rendering of subdivision surfaces whose goal is to make subdivision faces as easy to render as triangles, points, or lines. Our approach uses the GPU tessellation hardware and processes each face of a base mesh independently and in a streaming fashion, thus allowing an entire model to be rendered in a single pass. |
| [video][bibtex][project page] |

| PiGraphs: Learning Interaction Snapshots from Observations |
|---|
| Manolis Savva, Angel X. Chang, Pat Hanrahan, Matthew Fisher, Matthias Nießner |
| ACM Transactions on Graphics 2016 (TOG) |
| We learn a probabilistic model connecting human poses and arrangements of objects from observations of interactions collected with commodity RGB-D sensors. This model is encoded as a set of Prototypical Interaction Graphs (PiGraphs): a human-centric representation capturing physical contact and attention linkages between geometry and the human body. |
| [video][bibtex][project page] |

| ProxImaL: Efficient Image Optimization using Proximal Algorithms |
|---|
| Felix Heide, Steven Diamond, Matthias Nießner, Jonathan Ragan-Kelley, Wolfgang Heidrich, Gordon Wetzstein |
| ACM Transactions on Graphics 2016 (TOG) |
| ProxImaL is a domain-specific language and compiler for image optimization problems that makes it easy to experiment with different problem formulations and algorithm choices. The compiler intelligently chooses the best way to translate a problem formulation and choice of optimization algorithm into an efficient solver implementation. |
| [bibtex][supplemental][project page] |

| Face2Face: Real-time Face Capture and Reenactment of RGB Videos |
|---|
| Justus Thies, Michael Zollhöfer, Marc Stamminger, Christian Theobalt, Matthias Nießner |
| CVPR 2016 (Oral) |
| We present a novel approach for real-time facial reenactment of a monocular target video sequence (e.g., Youtube video). The source sequence is also a monocular video stream, captured live with a commodity webcam. Our goal is to animate the facial expressions of the target video by a source actor and re-render the manipulated output video in a photo-realistic fashion. |
| [video][bibtex][supplemental][project page] |
| Volumetric and Multi-View CNNs for Object Classification on 3D Data |
|---|
| Charles Ruizhongtai Qi, Hao Su, Matthias Nießner, Angela Dai, Mengyuan Yan, Leonidas Guibas |
| CVPR 2016 (Spotlight) |
| In this paper, we improve both Volumetric CNNs and Multi-view CNNs by introducing new distinct network architectures. Overall, we are able to outperform current state-of-the-art methods for both Volumetric CNNs and Multi-view CNNs. |
| [code][bibtex][supplemental][project page] |
2015

| Real-time Expression Transfer for Facial Reenactment |
|---|
| Justus Thies, Michael Zollhöfer, Matthias Nießner, Levi Valgaerts, Marc Stamminger, Christian Theobalt |
| ACM Transactions on Graphics 2015 (TOG) |
| We present a method for the real-time transfer of facial expressions from an actor in a source video to an actor in a target video, thus enabling the ad-hoc control of the facial expressions of the target actor. |
| [video][bibtex][project page] |

| Activity-centric Scene Synthesis for Functional 3D Scene Modeling |
|---|
| Matthew Fisher, Manolis Savva, Yangyan Li, Pat Hanrahan, Matthias Nießner |
| ACM Transactions on Graphics 2015 (TOG) |
| We present a novel method to generate 3D scenes that allow the same activities as real environments captured through noisy and incomplete 3D scans. |
| [video][bibtex][supplemental][project page] |

| SemanticPaint: Interactive 3D Labeling and Learning at your Fingertips |
|---|
| Julien Valentin, Vibhav Vineet, Ming-Ming Cheng, David Kim, Jamie Shotton, Pushmeet Kohli, Matthias Nießner, Antonio Criminisi, Shahram Izadi, Philip H. S. Torr |
| ACM Transactions on Graphics 2015 (TOG) |
| We present a new interactive and online approach to 3D scene understanding. Our system, SemanticPaint, allows users to simultaneously scan their environment, while interactively segmenting the scene simply by reaching out and touching any desired object or surface. |
| [video][bibtex][project page] |
| Efficient Ray Tracing of Subdivision Surfaces using Tessellation Caching |
|---|
| Carsten Benthin, Sven Woop, Matthias Nießner, Kai Selgrad, Ingo Wald |
| High Performance Graphics 2015 |
| In this paper, we propose method to efficiently ray trace subdivision surfaces using a lazy-build caching scheme while exploiting the capabilities of today's many-core architectures. Our approach is part of Intel's Embree. |
| [video][code][bibtex][project page] |

| Real-time Rendering Techniques with Hardware Tessellation |
|---|
| Matthias Nießner, Benjamin Keinert, Matthew Fisher, Marc Stamminger, Charles Loop, Henry Schäfer |
| Computer Graphics Forum 2015 |
| In this survey, we provide an overview of real-time rendering techniques with hardware tessellation by summarizing, discussing, and comparing state-of-the art approaches. |
| [bibtex][project page] |

| Shading-based Refinement on Volumetric Signed Distance Functions |
|---|
| Michael Zollhöfer, Angela Dai, Matthias Innmann, Chenglei Wu, Marc Stamminger, Christian Theobalt, Matthias Nießner |
| ACM Transactions on Graphics 2015 (TOG) |
| We present a novel method to obtain fine-scale detail in 3D reconstructions generated with low-budget RGB-D cameras or other commodity scanning devices. |
| [video][bibtex][project page] |
| Exploiting Uncertainty in Regression Forests for Accurate Camera Relocalization |
|---|
| Julien Valentin, Matthias Nießner, Jamie Shotton, Andrew Fitzgibbon, Shahram Izadi, Philip H. S. Torr |
| CVPR 2015 |
| In this paper, we train a regression forest to predict mixtures of anisotropic 3D Gaussians and show how the predicted uncertainties can be taken into account for continuous pose optimization. Experiments show that our method is able to relocalize up to 40 percent more frames than the state of the art. |
| [video][bibtex][project page] |

| Incremental Dense Semantic Stereo Fusion for Large-Scale Semantic Scene Reconstruction |
|---|
| Vibhav Vineet, Ondrej Miksik, Morten Lidegaard, Matthias Nießner, Stuart Golodetz, Victor A. Prisacariu, Olaf Kähler, David W. Murray, Shahram Izadi, Patrick Pérez, Philip H. S. Torr |
| ICRA 2015 |
| In this paper, we build on a recent hash-based technique for large-scale fusion and an efficient mean-field inference algorithm for densely-connected CRFs to present what to our knowledge is the first system that can perform dense, large-scale, outdoor semantic reconstruction of a scene in (near) real time. |
| [video][bibtex][project page] |
| The Semantic Paintbrush: Interactive 3D Mapping and Recognition in Large Outdoor Spaces |
|---|
| Ondrej Miksik, Vibhav Vineet, Morten Lidegaard, Ram Prasaath, Matthias Nießner, Stuart Golodetz, Stephen L. Hicks, Patrick Pérez, Shahram Izadi, Philip H. S. Torr |
| CHI 2015 |
| We present an augmented reality system for large scale 3D reconstruction and recognition in outdoor scenes. Unlike existing prior work, which tries to reconstruct scenes using active depth cameras, we use a purely passive stereo setup, allowing for outdoor use and extended sensing range. |
| [bibtex][project page] |

| Database-Assisted Object Retrieval for Real-Time 3D Reconstruction |
|---|
| Yangyan Li, Angela Dai, Leonidas Guibas, Matthias Nießner |
| Eurographics 2015 |
| We present a novel reconstruction approach based on retrieving objects from a 3D shape database while scanning an environment in real-time. With this approach, we are able to replace scanned RGB-D data with complete, hand-modeled objects from shape databases. |
| [video][bibtex][project page] |
| Dynamic Feature-Adaptive Subdivision |
|---|
| Henry Schäfer, Jens Raab, Mark Meyer, Marc Stamminger, Matthias Nießner |
| I3D 2015 |
| In this paper, we present dynamic feature-adaptive subdivision (DFAS), which improves upon FAS by enabling an independent subdivision depth for every irregularity. |
| [video][bibtex][project page] |
2014

| SceneGrok: Inferring Action Maps in 3D Environments |
|---|
| Manolis Savva, Angel X. Chang, Pat Hanrahan, Matthew Fisher, Matthias Nießner |
| ACM Transactions on Graphics 2014 (TOG) |
| In this paper, we present a method to establish a correlation between the geometry and the functionality of 3D environments. |
| [video][bibtex][project page] |

| Real-time Shading-based Refinement for Consumer Depth Cameras |
|---|
| Chenglei Wu, Michael Zollhöfer, Matthias Nießner, Marc Stamminger, Shahram Izadi, Christian Theobalt |
| ACM Transactions on Graphics 2014 (TOG) |
| We present the first real-time method for refinement of depth data using shape-from-shading in general uncontrolled scenes. |
| [video][code][bibtex][project page] |

| Real-time Non-rigid Reconstruction using an RGB-D Camera |
|---|
| Michael Zollhöfer, Matthias Nießner, Shahram Izadi, Christoph Rhemann, Christopher Zach, Matthew Fisher, Chenglei Wu, Andrew Fitzgibbon, Charles Loop, Christian Theobalt, Marc Stamminger |
| ACM Transactions on Graphics 2014 (TOG) |
| We present a combined hardware and software solution for markerless reconstruction of non-rigidly deforming physical objects with arbitrary shape in real-time. |
| [video][bibtex][project page] |

| Real-Time Deformation of Subdivision Surfaces from Object Collisions |
|---|
| Henry Schäfer, Benjamin Keinert, Matthias Nießner, Christoph Buchenau, Michael Guthe, Marc Stamminger |
| High Performance Graphics 2014 |
| We present a novel real-time approach for fine-scale surface deformations resulting from collisions. |
| [video][bibtex][project page] |

| Local Painting and Deformation of Meshes on the GPU |
|---|
| Henry Schäfer, Benjamin Keinert, Matthias Nießner, Marc Stamminger |
| Computer Graphics Forum 2014 |
| We present a novel method to adaptively apply modifications to scene data stored in GPU memory. Such modifications may include interactive painting and sculpting operations in an authoring tool, or deformations resulting from collisions between scene objects detected by a physics engine. |
| [video][bibtex][project page] |

| RetroDepth: 3D Silhouette Sensing for High-Precision Input On and Above Physical Surfaces |
|---|
| David Kim, Shahram Izadi, Jakub Dostal, Christoph Rhemann, Cem Keskin, Christopher Zach, Jamie Shotton, Tim Large, Steven Bathiche, Matthias Nießner, Alex Butler, Sean Fanello, Vivek Pradeep |
| CHI 2014 |
| We present RetroDepth, a new vision-based system for accurately sensing the 3D silhouettes of hands, styluses, and other objects, as they interact on and above physical surfaces. |
| [video][bibtex][project page] |

| State of the Art Report on Real-time Rendering with Hardware Tessellation |
|---|
| Henry Schäfer, Matthias Nießner, Benjamin Keinert, Marc Stamminger, Charles Loop |
| Eurographics 2014 |
| In this state of the art report, we provide an overview of recent work and challenges in this topic by summarizing, discussing and comparing methods for the rendering of smooth and highly detailed surfaces in real-time. |
| [bibtex][project page] |

| Combining Inertial Navigation and ICP for Real-time 3D Surface Reconstruction |
|---|
| Matthias Nießner, Angela Dai, Matthew Fisher |
| Eurographics 2014 |
| We present a novel method to improve the robustness of real-time 3D surface reconstruction by incorporating inertial sensor data when determining inter-frame alignment. With commodity inertial sensors, we can significantly reduce the number of iterative closest point (ICP) iterations required per frame. |
| [video][bibtex][project page] |
2013

| Real-time 3D Reconstruction at Scale using Voxel Hashing |
|---|
| Matthias Nießner, Michael Zollhöfer, Shahram Izadi, Marc Stamminger |
| ACM Transactions on Graphics 2013 (TOG) |
| Online 3D reconstruction is gaining newfound interest due to the availability of real-time consumer depth cameras. We contribute an online system for large and fine scale volumetric reconstruction based on a memory and speed efficient data structure. |
| [video][code][bibtex][project page] |

| Analytic Displacement Mapping using Hardware Tessellation |
|---|
| Matthias Nießner, Charles Loop |
| ACM Transactions on Graphics 2013 (TOG) |
| Displacement mapping is ideal for modern GPUs since it enables high-frequency geometric surface detail on models with low memory I/O. We provide a comprehensive solution to these problems by introducing a smooth analytic displacement function. |
| [bibtex][project page] |
| Real-time Collision Detection for Dynamic Hardware Tessellated Objects |
|---|
| Matthias Nießner, Christian Siegl, Henry Schäfer, Charles Loop |
| Eurographics 2013 |
| We present a novel method for real-time collision detection of patch based, displacement mapped objects using hardware tessellation. Our method supports fully animated, dynamically tessellated objects and runs entirely on the GPU. |
| [bibtex][project page] |

| Rendering Subdivision Surfaces using Hardware Tessellation |
|---|
| Matthias Nießner |
| PhD Thesis (Published by Dr. Hut) |
| In this thesis we present techniques that facilitate the use of high-quality movie content in real-time applications that run on commodity desktop computers. We utilize modern graphics hardware and use hardware tessellation to generate surface geometry on-the-fly based on patches. |
| [bibtex][project page] |

| Real-time Simulation of Human Vision using Temporal Compositing with CUDA on the GPU |
|---|
| Matthias Nießner, Nadine Kuhnert, Kai Selgrad, Marc Stamminger, Georg Michelson |
| Proceedings 25th Workshop on Parallel Systems and Algorithms 2013 |
| We present a novel approach that simulates human vision including visual defects such as glaucoma by temporal composition of human vision in real-time on the GPU. Therefore, we determine eye focus points every time step and adapt the lens accommodation of our virtual eye model accordingly. |
| [bibtex][project page] |
2012

| Feature Adaptive GPU Rendering of Catmull-Clark Subdivision Surfaces |
|---|
| Matthias Nießner, Charles Loop, Mark Meyer, Tony DeRose |
| ACM Transactions on Graphics 2012 (TOG) |
| We present a novel method for high-performance GPU based rendering of Catmull-Clark subdivision surfaces. Unlike previous methods, our algorithm computes the true limit surface up to machine precision, and is capable of rendering surfaces that conform to the full RenderMan specification for Catmull-Clark surfaces. |
| [video][code][bibtex][project page] |

| Patch-based Occlusion Culling for Hardware Tessellation |
|---|
| Matthias Nießner, Charles Loop |
| Computer Graphics International 2012 |
| We present an occlusion culling algorithm that leverages the unique characteristics of patch primitives within the hardware tessellation pipeline. |
| [bibtex][project page] |

| Efficient Evaluation of Semi-Smooth Creases in Catmull-Clark Subdivision Surfaces |
|---|
| Matthias Nießner, Charles Loop, Günther Greiner |
| Eurographics 2012 |
| We present a novel method to evaluate semi-smooth creases in Catmull-Clark subdivision surfaces. Our algorithm supports both integer and fractional crease tags corresponding to the RenderMan (Pixar) specification. |
| [bibtex][project page] |

| Real-time Simulation and Visualization of Human Vision through Eyeglasses on the GPU |
|---|
| Matthias Nießner, Roman Sturm, Günther Greiner |
| ACM SIGGRAPH VRCAI 2012 |
| We present a novel approach that allows real-time simulation of human vision through eyeglasses. Our system supports glasses that are composed of a combination of spheric, toric and in particular of free-form surfaces. |
| [bibtex][project page] |