SemanticPaint: Interactive 3D Labeling and Learning at your Fingertips
1University of Oxford 2Stanford University 3Nankai University 4Microsoft Research 5Technical University of Munich
ACM Transactions on Graphics 2015 (TOG)
Abstract
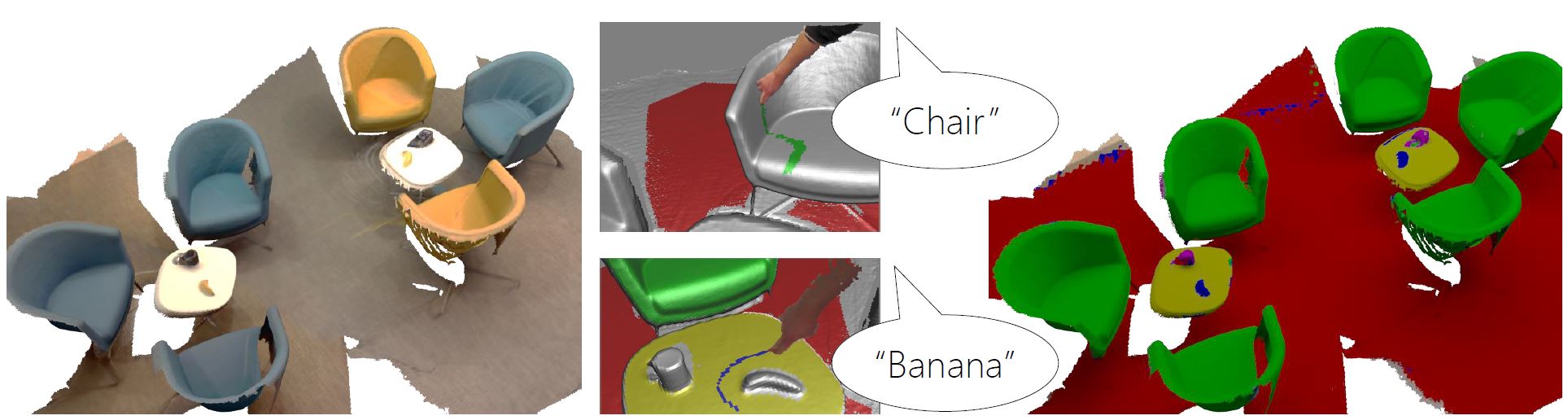
We present a new interactive and online approach to 3D scene understanding. Our system, SemanticPaint, allows users to simultaneously scan their environment, whilst interactively segmenting the scene simply by reaching out and touching any desired object or surface. Our system continuously learns from these segmentations, and labels new unseen parts of the environment. Unlike offline systems, where capture, labeling and batch learning often takes hours or even days to perform, our approach is fully online. This provides users with continuous live feedback of the recognition during capture, allowing them to immediately correct errors in the segmentation and/or learning – a feature that has so far been unavailable to batch and offline methods. This leads to models that are tailored or personalized specifically to the user’s environments and object classes of interest, opening up the potential for new applications in augmented reality, interior design, and human/robot navigation. It also provides the ability to capture substantial labeled 3D datasets for training large-scale visual recognition systems.
 Bibtex
Bibtex