Explicitly Modeled Attention Maps for Image Classification
1Technical University of Munich 2University of Freiburg 3University of Bonn
AAAI Conference on Artifical Intelligence (AAAI) 2021
Abstract
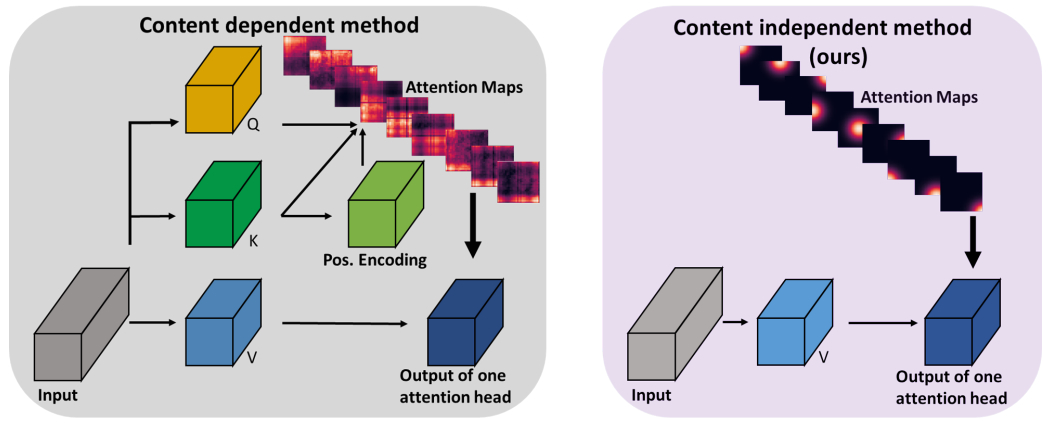
Self-attention networks have shown remarkable progress in computer vision tasks such as image classification. The main benefit of the self-attention mechanism is the ability to capture long-range feature interactions in attention-maps. However, the computation of attention-maps requires a learnable key, query, and positional encoding, whose usage is often not intuitive and computationally expensive. To mitigate this problem, we propose a novel self-attention module with explicitly modeled attention-maps using only a single learnable parameter for low computational overhead.
The design of explicitly modeled attention-maps using geometric prior is based on the observation that the spatial context for a given pixel within an image is mostly dominated by its neighbors, while more distant pixels have a minor contribution. Concretely, the attention-maps are parametrized via simple functions (e.g., Gaussian kernel) with a learnable radius, which is modeled independently of the input content.
Our evaluation shows that our method achieves an accuracy improvement of up to 2.2% over the ResNet-baselines in ImageNet ILSVRC and outperforms other self-attention methods such as AA-ResNet152 (Bello et al., 2019) in accuracy by 0.9% with 6.4% fewer parameters and 6.7% fewer GFLOPs.
 Bibtex
Bibtex